Prioriser les incidents
Vue d'ensemble
Avec potentiellement des centaines voire des milliers d'incidents de secrets publics à examiner, une priorisation efficace est essentielle pour concentrer vos efforts de remédiation sur les secrets qui présentent le plus grand risque pour votre organisation.
Ce guide explique les capacités disponibles pour vous aider à identifier les incidents nécessitant une attention immédiate et à mettre en place un workflow de remédiation efficace.
Sévérité et règles de sévérité
La sévérité est l'outil de priorisation principal, conçu pour consolider plusieurs facteurs de risque en un seul niveau de priorité actionnable.
Les niveaux de sévérité possibles sont : Critical, High, Medium, Low, Info, Unknown.
Comme la sévérité consolide les principaux principes de priorisation en une seule métrique, trier par sévérité est souvent le meilleur point de départ pour la revue d'incidents.
Règles de sévérité
Les règles de sévérité évaluent automatiquement les incidents en fonction de divers facteurs (type de secret, pertinence pour l'organisation, validité, indicateurs liés à l'entreprise) et attribuent les niveaux de priorité en conséquence.
Votre espace de travail est livré avec les règles de sévérité par défaut de GitGuardian, que vous pouvez personnaliser dans Settings > Severity rules pour correspondre aux priorités de risque spécifiques de votre organisation.
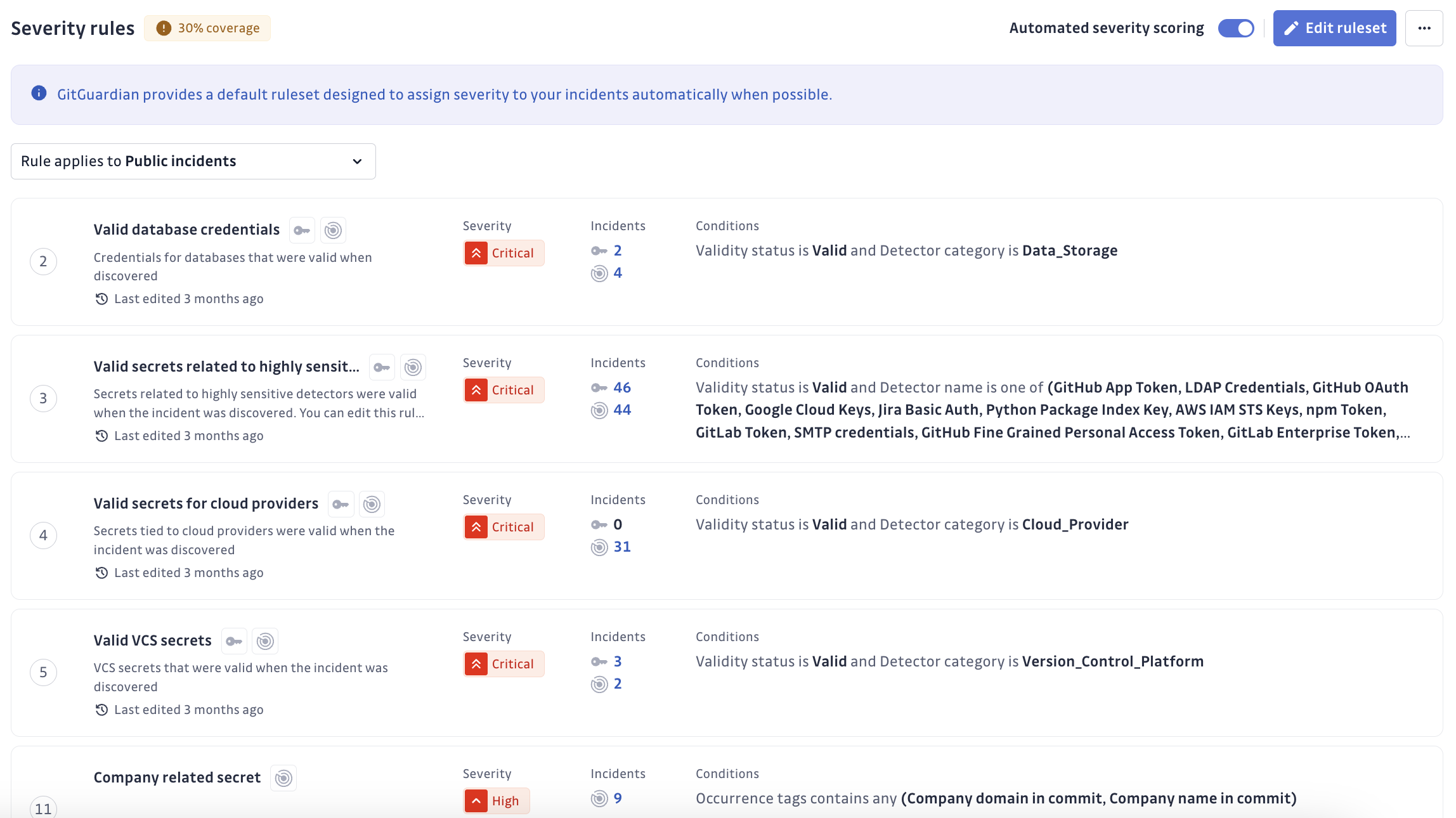
Lors de la création ou de la modification d'une règle de sévérité, vous pouvez préciser si elle s'applique aux incidents publics, aux incidents internes (provenant d'Internal Monitoring), ou aux deux.
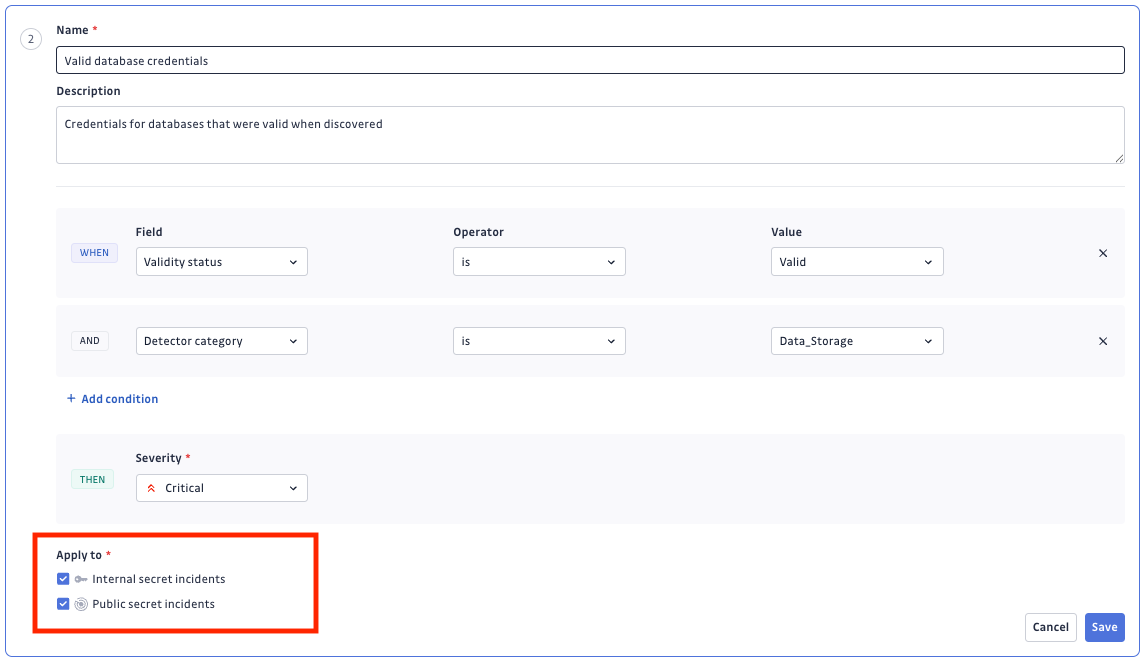
Certains critères de règles ne s'appliquent qu'à des types d'incidents spécifiques. Par exemple, les tags liés à l'entreprise sont propres à Public Monitoring : les règles utilisant ces critères désactiveront automatiquement l'option « internal incidents ».
Les incidents avec une sévérité « Unknown » indiquent qu'ils n'ont correspondu à aucune règle de sévérité configurée — ils peuvent nécessiter une revue manuelle ou la configuration de règles supplémentaires.
Surcharge manuelle de la sévérité
Vous pouvez modifier manuellement la sévérité d'un incident pour surcharger l'attribution automatique lorsque vous disposez de contexte supplémentaire ou que vous êtes en désaccord avec l'évaluation automatisée.
Outils de priorisation complémentaires
Bien que la sévérité fournisse une première priorisation automatisée, les outils additionnels ci-dessous vous aident à affiner votre approche et à gérer des scénarios spécifiques bénéficiant d'un contrôle plus granulaire.
Risk score (priorisation basée sur le ML)
Le risk score est une fonctionnalité basée sur l'ML qui évalue automatiquement le niveau de risque de chaque incident sur une échelle de 0 à 100, où 100 indique le risque le plus élevé nécessitant une attention immédiate et 0 indique le risque le plus faible. Il fournit une couche supplémentaire de priorisation en analysant plusieurs signaux de risque pour vous aider à vous concentrer sur les incidents qui posent la plus grande menace.
Le risk score complète le scoring de sévérité en fournissant une évaluation des risques plus granulaire et continuellement mise à jour.
Comment ça fonctionne
Le risk score est calculé en utilisant des modèles de machine learning qui prennent en compte divers facteurs notamment :
- Type de secret
- Validité (passée ou présente)
- Contexte de détection (fichiers de test, fichiers sensibles, environnement de production, etc.)
- Schémas d'exposition du secret
- Signaux contextuels supplémentaires
Le score est dynamique et se recalcule régulièrement pour refléter les changements dans le profil de risque de l'incident.
Utiliser le risk score dans votre workflow
Le risk score utilise des modèles de machine learning qui sont continuellement améliorés sur la base des retours utilisateurs. Si vous remarquez des incidents avec des scores ou des explications inattendus, nous vous encourageons à partager vos retours directement via le dashboard — votre contribution nous aide à affiner le modèle de scoring.
Dans la table des incidents
Le risk score peut être utilisé pour prioriser les incidents de plusieurs façons :
Filtrage et tri :
- Filtrer par plage de risk score : utilisez le filtre "Risk score" pour vous concentrer sur des niveaux de risque spécifiques (par exemple, Risk score ≥ 80 pour la priorité la plus élevée)
- Trier par risk score : sélectionnez "Sort by Risk score" pour ordonner les incidents par priorité
- Utiliser la vue sauvegardée "Critical" : cette vue préconfigurée affiche tous les incidents ouverts avec un risk score supérieur à 80/100, vous donnant un accès rapide aux incidents de plus haute priorité
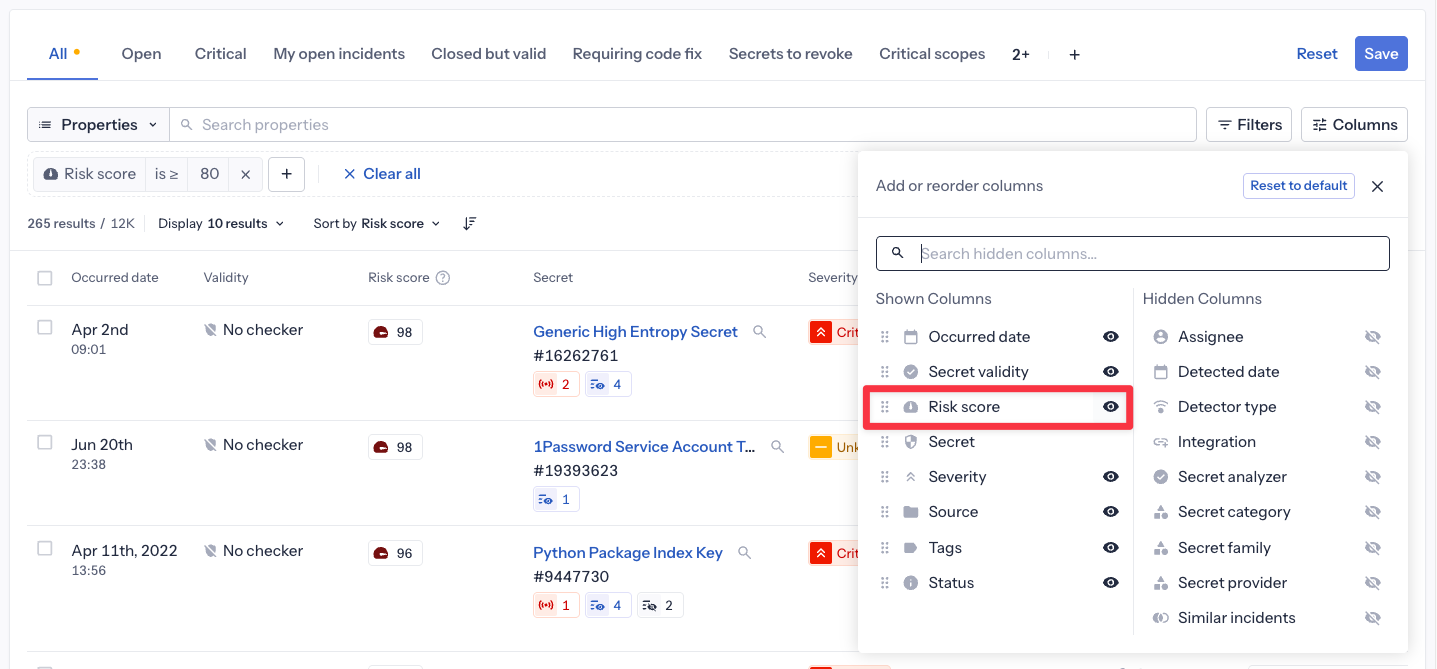
Ajouter la colonne Risk score :
Par défaut, la colonne risk score n'est pas affichée dans la table d'incidents. Pour voir les valeurs de score réelles :
- Cliquez sur le bouton Columns en haut à droite de la table d'incidents
- Trouvez "Risk score" dans la liste des colonnes disponibles
- Cliquez sur l'icône œil pour le rendre visible
- La colonne apparaîtra maintenant dans votre table, affichant le score de 0 à 100 pour chaque incident
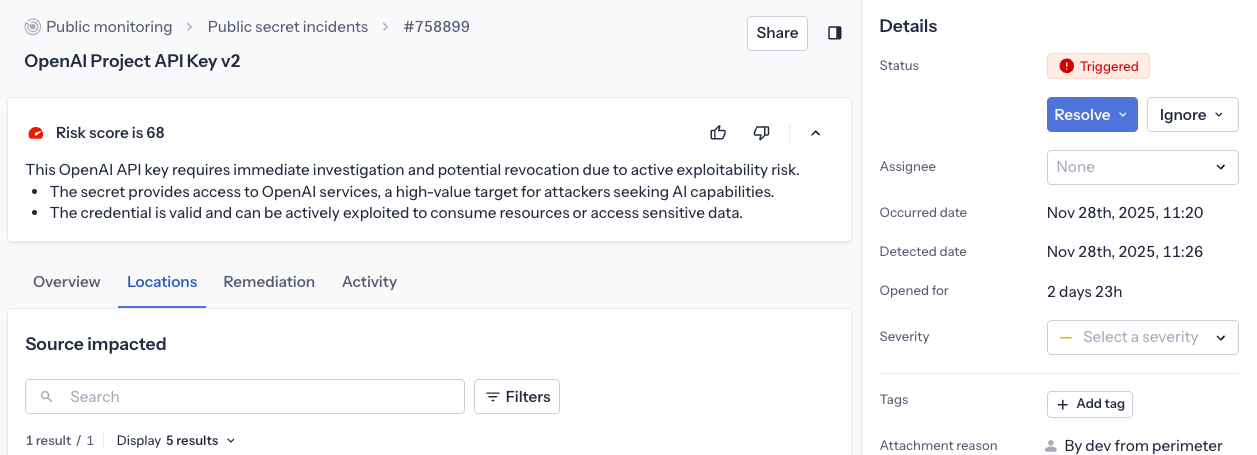
Dans la page détail de l'incident
Lors de l'investigation d'un incident, vous trouverez le risk score en haut de la page de détail de l'incident affichant :
- Le risk score actuel (0-100) avec un indicateur visuel
- Une explication détaillée de ce qui détermine le score, basée sur le contexte et les caractéristiques de l'incident, afin que vous sachiez quoi prioriser.
- Boutons de retour pour nous aider à améliorer la fonctionnalité (pouce vers le haut/bas)
Note pour les incidents publics :
Pour les incidents publics, le risk score reflète le risque technique du secret lui-même, et non sa pertinence pour votre entreprise. Pour évaluer le risque réel pour votre organisation, combinez le risk score avec les indicateurs de relation à l'entreprise (comme le domaine de l'e-mail de l'auteur ou la propriété du dépôt).
Évolution du score :
Le risk score est dynamique et se recalcule régulièrement à mesure que le contexte de l'incident évolue. Les changements dans le contexte de détection, les schémas d'exposition ou d'autres signaux de risque peuvent amener le score à s'ajuster au fil du temps. De plus, notre modèle ML est continuellement amélioré, ce qui peut conduire à des affinements de score.
Donner un retour :
Vos retours nous aident à améliorer continuellement le modèle ML. Sur la page de détail de l'incident, vous pouvez :
- Examiner le risk score et son explication
- Utiliser le bouton pouce vers le haut si le score reflète précisément le risque, ou le bouton pouce vers le bas si le score ne correspond pas à votre évaluation
- Développer/réduire l'explication à l'aide du bouton flèche
Les retours sont examinés par notre équipe pour affiner régulièrement l'algorithme de scoring.
Risk score vs. sévérité
Les deux outils aident à la priorisation mais servent des objectifs différents :
| Fonctionnalité | Risk Score | Sévérité |
|---|---|---|
| Calcul | Basé sur l'ML, automatique | Basé sur des règles, peut être manuel |
| Granularité | Échelle 0-100 | 6 niveaux (Critical à Unknown) |
| Mises à jour | Dynamique, se recalcule automatiquement | Statique sauf si modifié manuellement ou règles recalculées |
| Idéal pour | Évaluation des risques granulaire | Catégorisation basée sur les politiques |
Table des incidents
La table des incidents de secrets publics est l'endroit où vous appliquerez ces stratégies de priorisation par sévérité, ainsi que des capacités supplémentaires de filtrage et de tri. Elle propose plusieurs outils pour vous aider à avoir une vue plus claire de votre liste d'incidents.
Filtrage et tri
Au-delà de la sévérité, utilisez des filtres supplémentaires pour une priorisation plus ciblée :
- Pertinence organisationnelle : attachment reasons, tags liés à l'entreprise, propriétés de vault
- Indicateurs de risque : validité du secret, type de secret
- Autres tags d'information contextuelle.
Saved views
Créez et enregistrez des combinaisons de filtres pour accéder rapidement à des ensembles d'incidents spécifiques. GitGuardian fournit des vues par défaut pour vous aider à démarrer, mais vous pouvez construire des saved views personnalisées basées sur vos stratégies de filtrage les plus fréquentes.
Tags personnalisés
Créez et attribuez vos propres tags personnalisés pour marquer des incidents pour vos workflows spécifiques. Ces tags personnalisés peuvent ensuite être utilisés dans les filtres et les saved views afin de répondre aux besoins uniques de priorisation de votre organisation.
Capacités supplémentaires pour les Generic secrets
Les incidents Generic — chaînes à forte entropie qui n'ont pas pu être rattachées à un détecteur spécifique — peuvent être difficiles à évaluer au premier regard. Il est souvent compliqué de déterminer leur criticité.
Pour répondre à ce défi, GitGuardian utilise un modèle de machine learning spécialisé qui analyse le contexte autour des generic secrets. Cette analyse peut souvent déterminer la catégorie, la famille et le fournisseur du secret, fournissant des informations précieuses pour la priorisation.
Apprenez-en plus sur le generic secret enricher.
Ces informations enrichies fournissent des colonnes et filtres supplémentaires spécifiquement conçus pour prioriser plus efficacement les incidents de generic secrets.
Étapes suivantes : de la priorisation à la remédiation
Une fois vos incidents publics les plus critiques identifiés et priorisés, vous êtes prêt à commencer la remédiation systématique.
Ce que vous devriez avoir après la priorisation :
- Une liste ciblée d'incidents prioritaires qui appartiennent clairement à votre organisation
- Évaluation des risques — comprendre quels secrets représentent la plus grande menace
- Organisation du workflow — incidents critiques d'abord, les moins urgents planifiés ensuite
- Critères clairs — règles établies pour distinguer la priorité immédiate de la priorité standard
Passez à la phase de remédiation pour :
- Distinguer les incidents nécessitant une action immédiate de ceux qui peuvent être ignorés
- Engager les développeurs et parties prenantes pour les menaces confirmées
- Suivre des procédures de remédiation structurées pour les expositions publiques
- Mettre en place des procédures de nettoyage et de surveillance appropriées

