Investiguer les incidents publics
Comprendre les incidents publics
Avant de pouvoir prioriser ou remédier les incidents de secrets publics, vous devez comprendre ce que représente chaque incident et s'il est pertinent pour votre organisation. Identifier si les fuites de secrets sont liées à votre organisation et représentent une menace directe est le défi le plus crucial — et pourtant essentiel pour une priorisation, une investigation et une remédiation efficaces.
Ce guide explique tout le contexte et toutes les informations que GitGuardian fournit pour chaque fuite de secret, afin de vous aider à évaluer la pertinence pour votre organisation et à remédier efficacement.
Pour chaque incident public, GitGuardian fournit des métadonnées complètes pour vous aider à comprendre la portée et l'impact :
Risk score
Chaque incident public inclut un risk score (0–100, où 100 indique le risque le plus élevé et 0 le plus faible) qui fournit une priorisation basée sur le ML, fondée sur le risque technique du secret exposé. Le score est affiché en bonne place sur la page détail de l'incident, accompagné d'une explication détaillée des facteurs contributifs.
Important pour les incidents publics : le risk score reflète le risque technique du secret lui-même (validité, type, exposition), et non sa pertinence pour votre entreprise. Combinez le risk score avec les indicateurs de relation à l'entreprise pour évaluer le risque réel pour votre organisation.
Caractéristiques clés :
- Scoring dynamique qui se met à jour à mesure que le contexte de l'incident évolue
- Explication en langage naturel des principaux facteurs de risque
- Mécanisme de feedback pour aider à améliorer la fonctionnalité
→ En savoir plus sur le risk score et son utilisation
Détail du secret
Chaque incident public fournit des informations détaillées sur le secret lui-même :
Information sur le détecteur
Le détecteur identifie le type de secret trouvé. Cela vous aide à comprendre quel service ou système pourrait être compromis.
Validité du secret
GitGuardian effectue des vérifications de validité lorsque c'est possible afin de déterminer si le secret détecté est toujours actif et utilisable. Les secrets valides présentent des risques de sécurité immédiats et, lorsqu'ils sont liés à votre entreprise, doivent être priorisés pour une remédiation rapide.
Résultats du secret analyzer
Pour certains détecteurs, lorsque le secret est valide, notre secret analyzer fournit un contexte supplémentaire sur les permissions et le périmètre du secret. Cette analyse vous aide à comprendre l'impact potentiel si le secret venait à être exploité.
Détail des occurrences
La table des occurrences vous fournit les informations détaillées dont vous avez besoin :
- Identité de l'auteur : le nom et l'e-mail Git associés au commit
- Horodatage du commit : à quel moment l'occurrence du secret a été commitée
- Dépôt : le dépôt GitHub où le secret a été trouvé
- Hash du commit : le commit spécifique contenant le secret
- Chemin du fichier : le fichier exact et son emplacement dans le dépôt
- Aperçu du patch : un extrait de code montrant le secret en contexte (peut être masqué pour les patches volumineux)
- Lien GitHub : lien direct pour consulter l'occurrence sur GitHub (lorsque toujours visible publiquement)
- Indicateur de présence : indique si l'occurrence est toujours visible sur GitHub public. La valeur « removed from GitHub » indique généralement que le dépôt a été supprimé ou rendu privé après la fuite, ou que le commit lui-même a été supprimé.
Le fait que l'occurrence ait été effacée de GitHub ne signifie pas que l'incident est résolu ! Un acteur malveillant a pu cloner le dépôt et voir le secret avant qu'il ne soit effacé de GitHub.
Attachment reasons
Les attachment reasons expliquent pourquoi GitGuardian a associé un incident de secret public à votre organisation. Comprendre ces raisons aide à valider la pertinence de chaque incident :
- By developer from perimeter : l'un de vos développeurs surveillés est impliqué dans l'incident.
- On organization from perimeter : l'incident s'est produit sur un dépôt de l'une de vos organisations GitHub surveillées.
- From secret grasper : l'incident a été rattaché à votre entreprise grâce à un secret grasper présent dans le commit.
Les attachment reasons donnent un aperçu de la probabilité qu'une fuite soit liée à votre organisation. Les incidents rattachés « By developer from perimeter » peuvent contenir des secrets d'entreprise, mais peuvent tout aussi bien être des identifiants personnels sans rapport de vos développeurs. À l'inverse, les incidents divulgués « On organization from perimeter » sont liés à l'entreprise puisqu'ils proviennent des dépôts de votre organisation.
Tags et information contextuelle
GitGuardian applique automatiquement divers tags pour vous aider à évaluer et catégoriser rapidement les incidents :
Indicateurs d'incidents liés à l'entreprise
Plusieurs tags et indicateurs peuvent vous aider à identifier les incidents qui sont probablement liés à votre organisation :
- Company domain in commit : un de vos domaines surveillés apparaît dans le contenu du fichier de l'occurrence.
- Company name in commit : le nom de votre entreprise apparaît dans le patch où le secret est divulgué.
- Secret grasper in commit : un de vos secret graspers définis (que l'on peut voir comme des identifiants spécifiques à l'entreprise) apparaît dans le patch de l'occurrence.
- Context related to company : le moteur ML de GitGuardian a déterminé que le contexte autour de la fuite de secret semble lié à votre entreprise, sur la base de termes spécifiques à l'entreprise ou d'indicateurs de niveau entreprise.
- Internally leaked : ce tag (uniquement disponible si vous avez aussi Internal Monitoring) indique que le même secret a été trouvé dans un incident interne au sein de vos sources surveillées. La carte d'exploration vous montrera l'incident interne associé. Dans Internal Monitoring, cette relation est présentée comme le type d'exposition Public incident linked sur les secrets divulgués en interne. Voir Public exposure information pour plus de détails.
Autres tags
D'autres tags sont fournis par GitGuardian pour vous aider à évaluer la criticité probable des incidents :
- Sensitive file : une des occurrences de l'incident s'est produite sur un fichier potentiellement sensible.
- Production : le commit associé à l'une des occurrences semble lié à un environnement de production.
- Test file : une des occurrences de l'incident s'est produite sur un fichier potentiellement de test. Un fichier est automatiquement classé comme fichier de test si son chemin contient l'un des motifs suivants (avec uniquement des chiffres ou caractères spéciaux autour) : test/tests, example/examples, mock/mocks, fixture/fixtures, fake, dummy, false ou testdata. Par exemple, .test.env ou 00testdata.json correspondront, mais pas dummydata.json.
- False positive : le moteur ML de GitGuardian a identifié cela comme n'étant probablement pas un secret réel. Ces incidents peuvent généralement être ignorés en toute sécurité. (Apprenez-en plus ici)
- From historical scan : l'incident a été découvert lors d'un scan historique plutôt qu'en surveillance temps réel.
Carte d'exploration
Cette fonctionnalité apporte le plus de valeur lorsque vous utilisez aussi Internal Monitoring, NHI Governance, ou que vous avez intégré vos gestionnaires de secrets via GitGuardian Scout pour un contexte complet.
La carte d'exploration fournit une représentation visuelle des endroits où GitGuardian a détecté ce secret spécifique dans vos sources intégrées et de ce à quoi il donne potentiellement accès.
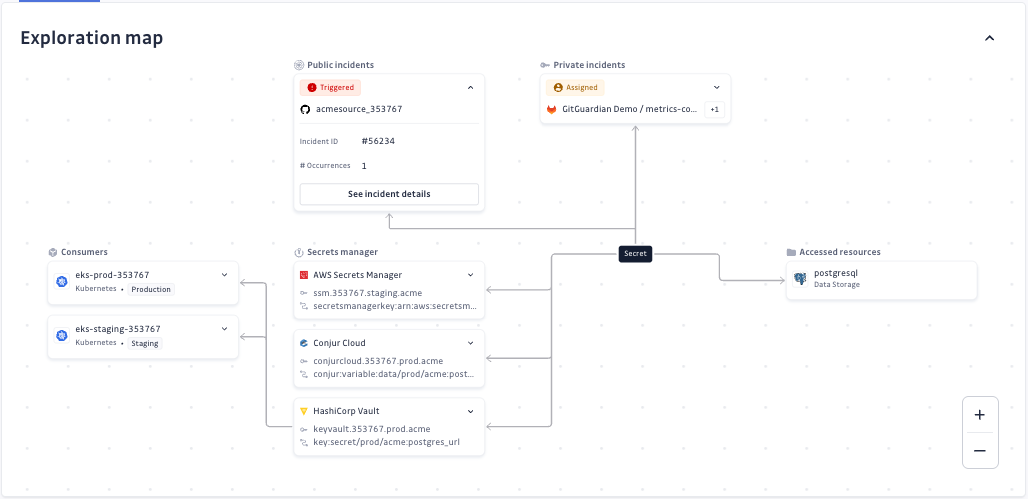
La carte peut révéler :
- Incidents internes (si vous utilisez Internal Monitoring) : si le secret apparaît également dans votre base de code interne, vos tickets JIRA, vos messages Slack ou d'autres sources internes
- Stockage en gestionnaire de secrets (si vous avez intégré des gestionnaires de secrets) : si le secret est stocké dans vos vaults ou gestionnaires de secrets
- Usage en infrastructure (si vous utilisez NHI Governance avec des intégrations d'infrastructure) : si le secret est utilisé dans des sources d'infrastructure comme GitLab CI ou des clusters Kubernetes
Pour les incidents de secrets publics, une carte d'exploration affichant plusieurs nœuds est l'indicateur le plus fort possible que ce secret appartient réellement à votre entreprise et nécessite une remédiation immédiate.
Regroupement d'incidents similaires basé sur le ML
Le regroupement d'incidents similaires basé sur l'ML est disponible pour les plans Business et Enterprise.
Le regroupement d'incidents similaires basé sur l'ML de GitGuardian vous aide à identifier et gérer les incidents liés plus efficacement en détectant automatiquement les incidents qui partagent des caractéristiques et un contexte similaires.
Comment ça fonctionne
Lors de la consultation d'une page de détail d'incident, vous verrez une section Similar Incidents dans la sidebar qui affiche les incidents avec des schémas similaires détectés par nos algorithmes de machine learning. Cette fonctionnalité analyse le contexte de code dans le patch pour identifier des relations significatives entre les incidents.
Scénarios courants de regroupement
L'algorithme ML identifie différents types d'incidents similaires :
- Tokens en rotation dans des fichiers automatisés : même fichier qui fuit en continu différents tokens via l'automatisation
- Credentials de test QA : clés de test (bots Slack, clés API Postman) apparaissant dans des contextes similaires
- Chaînes de connexion à la base de données : plusieurs chaînes de connexion vers le même environnement avec différents credentials
- Faux positifs répétés : chaînes à haute entropie dans les logs ou scripts de test qui sont probablement générés par le système
- Fuites de code de templating : plusieurs développeurs utilisant des tutoriels ou templates partagés avec des secrets divulgués similaires
- Schémas connus bruyants : faux positifs cohérents provenant de types de fichiers spécifiques ou de services internes
Utiliser les incidents similaires pour l'investigation
- Depuis les détails d'incident : visualisez les incidents similaires dans la sidebar et cliquez sur "Voir X incidents similaires" pour les voir dans la liste principale d'incidents
- Filtrer par similarité : dans la zone de recherche, utilisez
similar_topour n'afficher que les incidents similaires à un incident spécifique - Trier par nombre de similaires : utilisez la colonne "Incidents similaires" pour trier les incidents par nombre le plus élevé ou le plus bas d'incidents similaires
Cette fonctionnalité est particulièrement utile pour :
- Identifier les faux positifs : repérer les schémas qui indiquent des incidents faux positifs
- Remédiation cohérente : appliquer la même approche de remédiation aux incidents qui nécessitent des correctifs similaires
- Comprendre les schémas d'incidents : découvrir les problèmes récurrents dans votre codebase
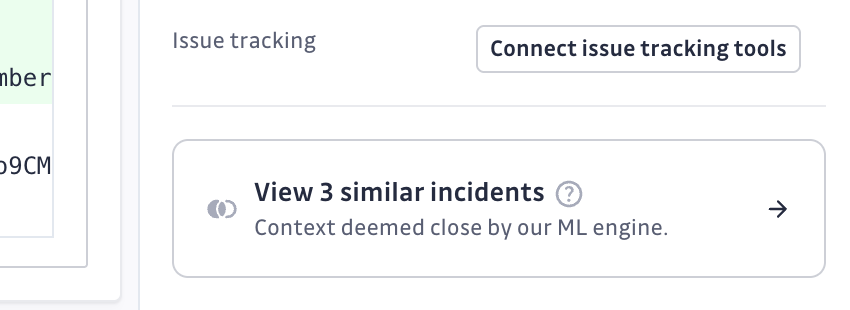
Lors de l'investigation d'incidents publics, le regroupement d'incidents similaires vous aide à :
- Identifier des motifs : repérer les problèmes récurrents provenant de développeurs ou de dépôts spécifiques
- Évaluer la pertinence organisationnelle : regrouper les incidents qui peuvent partager la même cause racine
- Prioriser efficacement : traiter les incidents liés ensemble plutôt qu'individuellement
Le regroupement d'incidents similaires utilise des modèles de machine learning qui sont continuellement améliorés sur la base des retours utilisateurs. Si vous remarquez des incidents avec des regroupements inattendus, nous vous encourageons à partager vos retours directement via le dashboard — votre contribution nous aide à affiner le modèle de regroupement.

