Machine learning
Détecter des secrets avec des résultats de haute qualité est une tâche complexe et minutieuse. Pour améliorer notre moteur de détection, nous avons mis en place divers modèles de machine learning pour analyser le code comme un développeur professionnel, identifier les faux positifs et enrichir les secrets génériques avec des informations contextuelles.
False Positive Remover
Seuls les workspaces avec un plan Business peuvent accéder à cette fonctionnalité.
Lorsqu'il s'agit d'éviter les faux positifs, nous avons poussé la programmation impérative et les expressions régulières à leurs limites. Il n'est tout simplement pas possible d'écrire des conditions ou des expressions régulières pour chaque scénario potentiel.
Pour surmonter cette contrainte technologique, nous avons mis en œuvre le machine learning afin d'entraîner les machines à naviguer rapidement et efficacement dans ce domaine complexe et à identifier les éléments que nous recherchons.
Le False Positive Remover identifie et étiquette avec précision les incidents comme « faux positifs » grâce à son analyse approfondie.
Le False Positive Remover s'exécute sur les résultats de toutes vos sources, pas seulement sur vos dépôts de code. Cela inclut les sources non-code telles que Confluence, Jira, Slack et Microsoft Teams. Chaque nouveau résultat provenant de ces sources passe automatiquement par le modèle, de sorte que les secrets génériques peuvent être détectés sur des sources non-code sans inonder votre dashboard de faux positifs.
- Pour les VCS, le False Positive Remover est un modèle développé et entraîné en interne, indépendant des services tiers, qui identifie et étiquette avec précision les incidents comme « faux positifs » grâce à son analyse approfondie.
- Pour les sources non-code, le filtrage des faux positifs repose sur un modèle basé sur un LLM et nécessite l'activation des fonctionnalités IA dans votre workspace. Voir Paramètres IA.
Comment l'utiliser ?
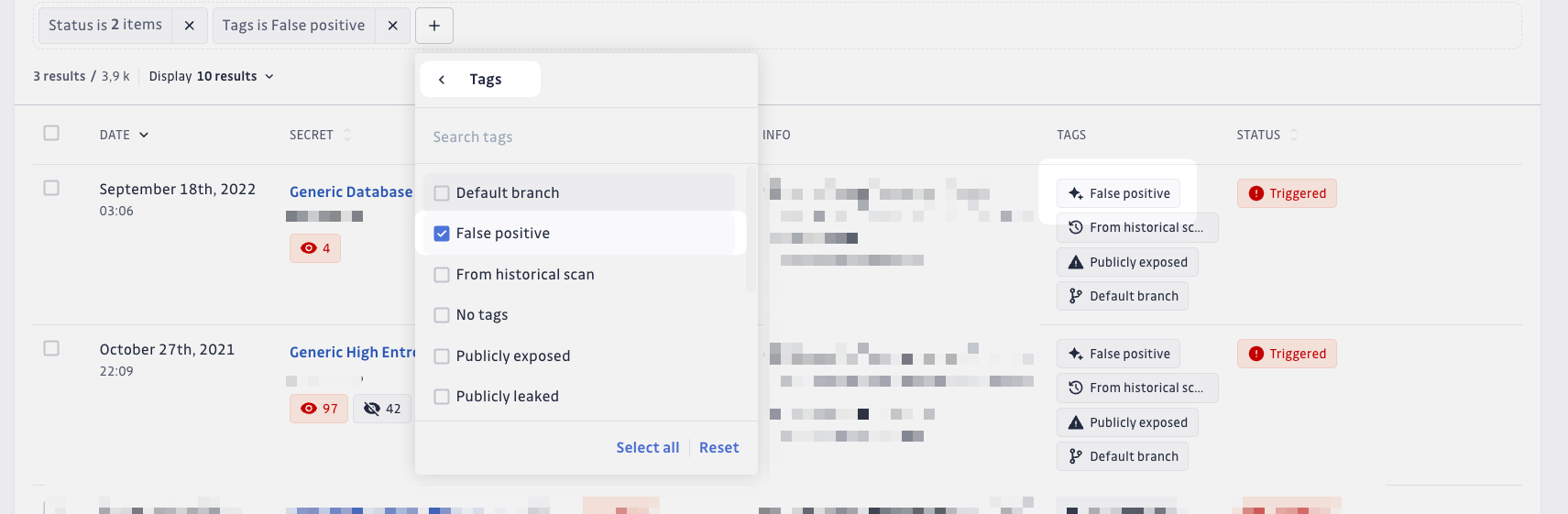
Vous pouvez améliorer votre workflow en utilisant le filtre Filters > GitGuardian tags > False positive situé sur la page de liste des incidents.
Ce filtre vous permet d'identifier et de gérer facilement les incidents de type faux positif, vous aidant ainsi à rationaliser votre processus de résolution des incidents.
Pour en savoir plus, lisez notre article de blog
FAQ
Que considère ce modèle comme « faux positif » ?
Quelque chose qui ne peut être un secret dans aucun contexte.
Dans l'exemple ci-dessous ("signup_form_confirm_password": " Confirmar contrasinal") ressemble à un vrai positif pour une regex mais pas pour notre modèle qui analyse un contexte (lignes avant/après)
{
"signup_form_username": "Identificador",
"signup_form_password": "Contrasinal",
"signup_form_confirm_password": " Confirmar contrasinal", <- a regex may consider this a true positive, not our model.
"signup_form_button_submit": "Crear conta",
}
S'il s'agit de faux positifs, pourquoi ne pas simplement les supprimer ?
Nous les �étiquetons comme faux positifs plutôt que de les supprimer afin que vous conserviez une visibilité complète et restiez maître de la situation. Vous pouvez les filtrer de votre vue et vous pouvez toujours consulter ce qui a été étiqueté.
Détectez-vous tous les faux positifs que j'ai ?
Le modèle fonctionne avec une haute précision (environ 95 %) pour éviter d'étiqueter de vrais secrets comme faux positifs. Sur les secrets génériques provenant de sources non-code, il filtre en moyenne 25 à 40 % des résultats. Nous continuons à améliorer le rappel au fil du temps tout en préservant la précision.
Secret Enricher
Secret Enricher est un modèle de machine learning spécialisé conçu pour analyser le contexte autour des secrets génériques et les classer automatiquement en catégories et fournisseurs. Cette classification enrichie vous aide à prioriser les efforts de remédiation en comprenant l'impact potentiel et la criticité de chaque incident.
Cette fonctionnalité est spécifiquement conçue pour les incidents génériques qui n'ont pas pu être associés à un détecteur spécifique. Le Secret Enricher analyse le contexte environnant afin de fournir des informations sur la catégorie et le fournisseur qui facilitent la priorisation et la remédiation.
Affichage des incidents piloté par l'enrichissement
Lorsque le Secret Enricher enrichit avec succès un incident générique, le nom du secret enrichi remplace automatiquement le nom du détecteur générique. Cela signifie qu'au lieu de voir des noms vagues comme « Generic Database Assignment » ou « Generic High Entropy Secret », vous verrez des noms précis et exploitables :
- Redis Identifiers au lieu de « Generic Database Assignment »
- Stripe API Key au lieu de « Generic High Entropy Secret »
- PostgreSQL Connection String au lieu de « Generic Database Assignment »
- AWS Access Key au lieu de « Generic High Entropy Secret »
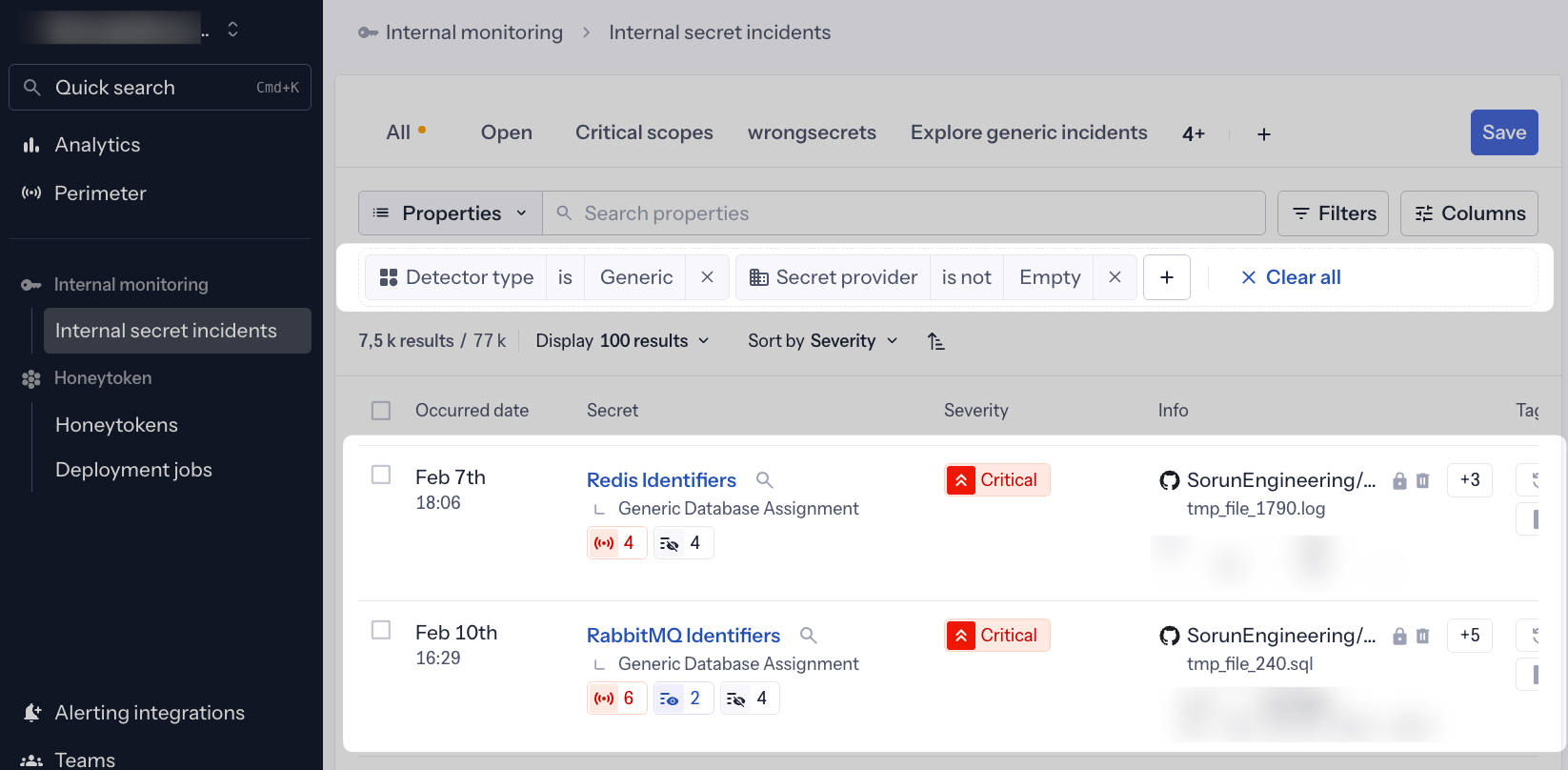
Cette UX pilotée par l'enrichissement fournit un contexte immédiat en un coup d'œil, éliminant le besoin d'ouvrir chaque incident pour comprendre quel type de secret a été exposé. Les noms enrichis apparaissent dans :
- Les listes d'incidents
- Les résultats de recherche
- Les réponses de l'API
- Les exports CSV et JSON
Dans certains cas, le nom du détecteur (par exemple, « Generic High Entropy Secret ») peut être visible au lieu du nom enrichi. Nous travaillons à cette harmonisation tout au long des premiers mois de 2026.
Comment les catégories du Secret Enricher facilitent la remédiation
Comprendre les catégories du Secret Enricher vous aide à :
- Prioriser les secrets d'infrastructure critique (fournisseurs cloud, bases de données, etc.)
- Vous concentrer sur les services à fort impact (systèmes de paiement, fournisseurs d'identité, etc.)
- Identifier les secrets susceptibles d'affecter les opérations métier (systèmes de messagerie, plateformes e-commerce, etc.)
- Rationaliser les workflows de remédiation en regroupant les types de secrets similaires
- Appliquer des politiques de sécurité appropriées en fonction du type de service
Comment l'utiliser ?
Noms enrichis dans les listes d'incidents
Les noms de secrets enrichis sont automatiquement affichés comme nom principal de l'incident dans vos listes d'incidents. Aucune configuration nécessaire — lorsque notre modèle ML identifie avec succès un type de secret, vous le voyez immédiatement.
Cette approche pilotée par l'enrichissement rend le triage des incidents plus rapide et plus intuitif. Vous pouvez identifier instantanément :
- Les identifiants de base de données (Redis, PostgreSQL, MongoDB)
- Les secrets de fournisseurs cloud (AWS, Azure, GCP)
- Les tokens de systèmes de paiement (Stripe, PayPal, Square)
- Les clés API pour des services spécifiques (Twilio, SendGrid, Slack)
Personnaliser vos vues
Depuis la liste des incidents, vous pouvez personnaliser l'affichage de vos incidents en cliquant sur le bouton « Columns » en haut à droite du tableau.
Cela vous permet d'ajouter les colonnes « Secret category » et « Secret provider », qui affichent des propriétés d'enrichissement supplémentaires déduites par le modèle à côté du nom du secret enrichi.
Grâce à cette personnalisation, vous pouvez rapidement repérer les catégories importantes (telles que « Data Storage ») ou les fournisseurs spécifiques qui pourraient nécessiter une attention immédiate parmi vos incidents.
Filtrer vos données
Trois filtres (Provider, Category, Family) vous aident à identifier les incidents génériques les plus importants ou critiques, tels que ceux classés sous « Data Storage » ou liés au fournisseur « Postgresql ».
Vous pouvez appliquer ces filtres de plusieurs manières :
Exemple 1 > Filtrer directement les incidents enrichis : Utilisez « Detector Type is Generic » + « Secret Provider is not Empty » pour trouver les secrets génériques enrichis avec au moins un fournisseur déduit
Exemple 2 > Regrouper les incidents génériques par Secret Category : Utilisez « Detector Type is Generic » + « Secret Category is Data Storage » pour trouver les secrets génériques enrichis liés à la gestion/stockage de données
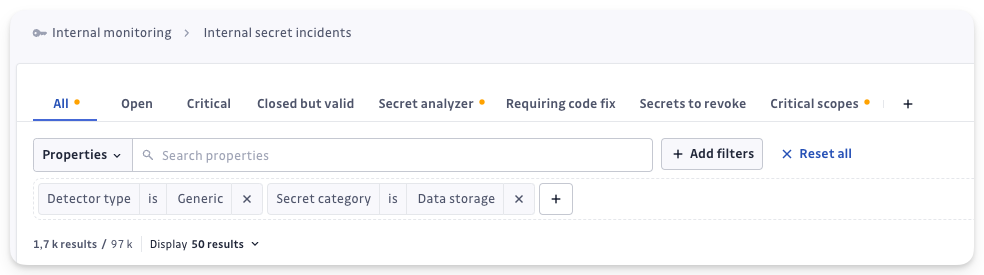
Avec ces filtres, vous pouvez explorer vos incidents enrichis et identifier rapidement ceux qui comptent le plus pour vos opérations.
Référence des catégories et fournisseurs
Pour les définitions détaillées de toutes les catégories et fournisseurs GSE, y compris ce qu'ils signifient et comment les prioriser, consultez notre référence complète des catégories et fournisseurs GSE.
FAQ
Que se passe-t-il si un secret ne peut pas être enrichi ?
Si le modèle ML ne peut pas identifier un fournisseur ou une catégorie avec suffisamment de confiance, l'incident conservera son nom de détecteur générique d'origine (comme « Generic Database Assignment »). Vous pouvez toujours utiliser nos capacités de filtrage pour retrouver et examiner ces incidents non enrichis.
Pourquoi ne sont-ils pas transformés en incidents spécifiques ?
Les incidents enrichis restent classés comme « génériques » du point de vue de la détection, car l'enrichissement repose sur une analyse contextuelle, et non sur des règles de détection basées sur des motifs. Cependant, le nom enrichi fournit la spécificité exploitable dont vous avez besoin pour la priorisation et la remédiation. Au fur et à mesure que nous affinons cette fonctionnalité, nos définitions deviendront plus précises, et nous pourrions convertir les enrichissements très fiables en détecteurs spécifiques.
Que le modèle est-il entraîné à découvrir ?
Le modèle peut identifier un ensemble complet de catégories et de fournisseurs :
Le modèle peut identifier les catégories suivantes :
- AI
- CDN
- CI/CD
- Cloud provider
- Code analysis
- Collaboration tool
- CRM
- Cryptos
- Data storage
- E-commerce
- Identity provider
- Internal
- Messaging system
- Monitoring
- Other
- Package registry
- Payment system
- Private key
- Remote access
- Secret management
- Social network
- Version control platform
Le modèle peut identifier des centaines de fournisseurs, notamment :
- Amazon AWS et services associés
- Microsoft Azure et services associés
- Google Cloud Platform
- Bases de données populaires (PostgreSQL, MySQL, MongoDB, Redis)
- Plateformes CI/CD (GitHub, GitLab, Jenkins, CircleCI)
- Systèmes de paiement (Stripe, PayPal, Square)
- Services d'IA (OpenAI, Anthropic, Hugging Face)
- Plateformes de messagerie (Slack, Discord, Twilio)
- Et bien d'autres...
Pour la liste complète des catégories et fournisseurs pris en charge, consultez la référence des catégories et fournisseurs GSE.
Score de risque (priorisation des incidents par ML)
Le score de risque est une fonctionnalité pilotée par le machine learning qui évalue automatiquement le niveau de risque de chaque incident sur une échelle de 0 à 100, où 100 indique le risque le plus élevé et 0 le plus faible. Il analyse de multiples signaux de risque, notamment le type de secret, sa validité, le contexte d'exposition et les schémas comportementaux, pour vous aider à vous concentrer sur les incidents qui représentent la plus grande menace.
Le risk score utilise des modèles de machine learning qui sont continuellement améliorés sur la base des retours utilisateurs. Si vous remarquez des incidents avec des scores ou des explications inattendus, nous vous encourageons à partager vos retours directement via le dashboard — votre contribution nous aide à affiner le modèle de scoring.
Capacités clés
- Évaluation automatique du risque pour tous les incidents de secrets (Internal Monitoring et Public Monitoring)
- Notation dynamique qui se met à jour à mesure que le contexte de l'incident évolue
- Explications en langage naturel générées pour chaque incident
- Priorisation granulaire avec une échelle de 0 à 100 pour affiner les workflows de remédiation
- Boucle de feedback pour l'amélioration future du modèle
Où l'utiliser
Le score de risque est disponible dans le cadre des fonctionnalités de priorisation et d'investigation des incidents :
Cette fonctionnalité s'inscrit dans l'initiative plus large de GitGuardian en matière de ML visant à améliorer à la fois la précision de la détection et l'efficacité de la remédiation.
Regroupement d'incidents similaires (par ML)
Le regroupement d'incidents similaires est une fonctionnalité pilotée par le machine learning qui identifie et regroupe automatiquement les incidents liés en fonction de similarités contextuelles. Au lieu d'examiner les incidents un par un, vous pouvez traiter des groupes entiers d'incidents similaires ensemble, accélérant considérablement votre workflow de remédiation.
Capacités clés
- Regroupement automatique des incidents partageant des caractéristiques similaires (contexte de code similaire dans le patch)
- Actions de remédiation en masse pour résoudre plusieurs incidents liés en une seule fois
- Mises à jour dynamiques des groupes au fur et à mesure que de nouveaux incidents sont détectés ou que des incidents existants sont résolus
Comment cela aide
Le regroupement d'incidents similaires vous aide à :
- Réduire le temps de remédiation en traitant des groupes d'incidents liés ensemble plutôt qu'individuellement
- Identifier les problèmes systémiques lorsque le même type de secret apparaît à plusieurs endroits
- Appliquer une remédiation cohérente à travers des incidents similaires pour maintenir la cohérence des politiques de sécurité
- Vous concentrer sur les incidents uniques en traitant rapidement les groupes d'incidents similaires en premier
Où l'utiliser
Le regroupement d'incidents similaires est disponible dans les workflows de remédiation des incidents :
Cette fonctionnalité s'inscrit dans l'initiative plus large de GitGuardian en matière de ML visant à améliorer à la fois la précision de la détection et l'efficacité de la remédiation.

