Prioriser les incidents
L'un des défis clés d'un programme de détection et de remédiation de secrets est de prioriser les incidents et d'identifier où concentrer vos efforts de remédiation.
La priorisation est la première étape de votre parcours de remédiation. Après avoir priorisé les incidents, vous devrez investiguer pour rassembler le contexte, puis enfin remédier pour traiter les plus critiques.
GitGuardian se concentre sur la précision de son moteur de détection de secrets (pour remonter le pourcentage le plus élevé de vrais positifs). Vous pouvez vous référer à notre documentation dédiée pour le moteur de détection de secrets de GitGuardian pour plus d'informations. Cela dit, la sévérité d'un incident de secret reste une notion difficile à appréhender depuis un point de vue externe. C'est pourquoi GitGuardian essaie de fournir autant d'informations factuelles que possible afin de vous aider à catégoriser la sévérité de l'incident de secret.
1. Prioriser avec la table d'incidents
Vous pouvez trouver une table de tous vos incidents dans la section Incident. Notre objectif est de vous aider à naviguer dans cette table de la manière la plus efficace possible.
Utiliser les vues sauvegardées
Prioriser efficacement les incidents est crucial pour une remédiation efficace. La fonctionnalité Vues sauvegardées vous permet d'accéder rapidement et de gérer vos ensembles de filtres préférés, en vous concentrant sur les incidents les plus importants sans ajuster les filtres de façon répétée.
Certaines vues sont préconfigurées par GitGuardian, fournissant un point de départ pour une gestion efficace des incidents :
- Open : voir tous les incidents actuellement ouverts qui nécessitent une attention.
- Critical : se concentrer sur les incidents ouverts avec un risk score supérieur à 80/100, mettant en évidence les incidents de plus haute priorité à traiter en premier.
- My open incidents : afficher les incidents assignés à l'utilisateur courant, permettant une gestion personnalisée des incidents.
- Closed but valid : examiner les incidents qui ont été résolus ou ignorés alors que le secret est encore marqué comme valide.
Les utilisateurs peuvent également créer leurs propres vues personnalisées pour s'adapter à leurs processus de remédiation spécifiques.
Incidents les plus récents
Par défaut, la table d'incidents est triée par incidents "les plus récents". En effet, les secrets qui ont été détectés le plus récemment ont la probabilité la plus élevée d'être valides et donc nuisibles. La date d'un incident est la date de sa première occurrence.
Il est particulièrement important de noter ici que GitGuardian crée des incidents de secrets pendant les analyses historiques. La date de ces incidents est la date du commit où l'exposition du secret s'est produite, pas la date de l'analyse historique. Ces incidents seront marqués avec le tag "From historical scan".
Par conséquent, vous pouvez vous retrouver avec des incidents très anciens lorsque vous exécutez GitGuardian sur votre historique git. C'est pourquoi nous vous permettons de modifier la période des incidents listés et de la définir sur All time. Par défaut, cette période est définie sur Last Month.
Aperçu du secret
Vous pouvez prévisualiser rapidement le secret réel depuis la table d'incidents avec un simple survol. Si vous souhaitez approfondir l'investigation, vous pouvez cliquer sur l'incident de secret et visiter sa page dédiée.
Soyez prudent : parfois le contexte plus large d'un secret peut être beaucoup plus nuisible que le secret lui-même. Nous recommandons toujours d'aller au-delà de l'aperçu du secret et de mener une investigation approfondie avant de prendre une décision sur un incident particulier.

Validité du secret
La table d'incidents indique pour chaque incident si le secret exposé est encore valide ou non. Vous pouvez également filtrer vos incidents pour ne voir que les secrets valides. Cela peut vous aider à prioriser vos incidents et à vous concentrer sur les secrets qui peuvent encore être exploités. Nous vous recommandons de prendre soin des credentials exposés et valides dès que possible, car ils représentent un risque d'exploitation plus élevé.
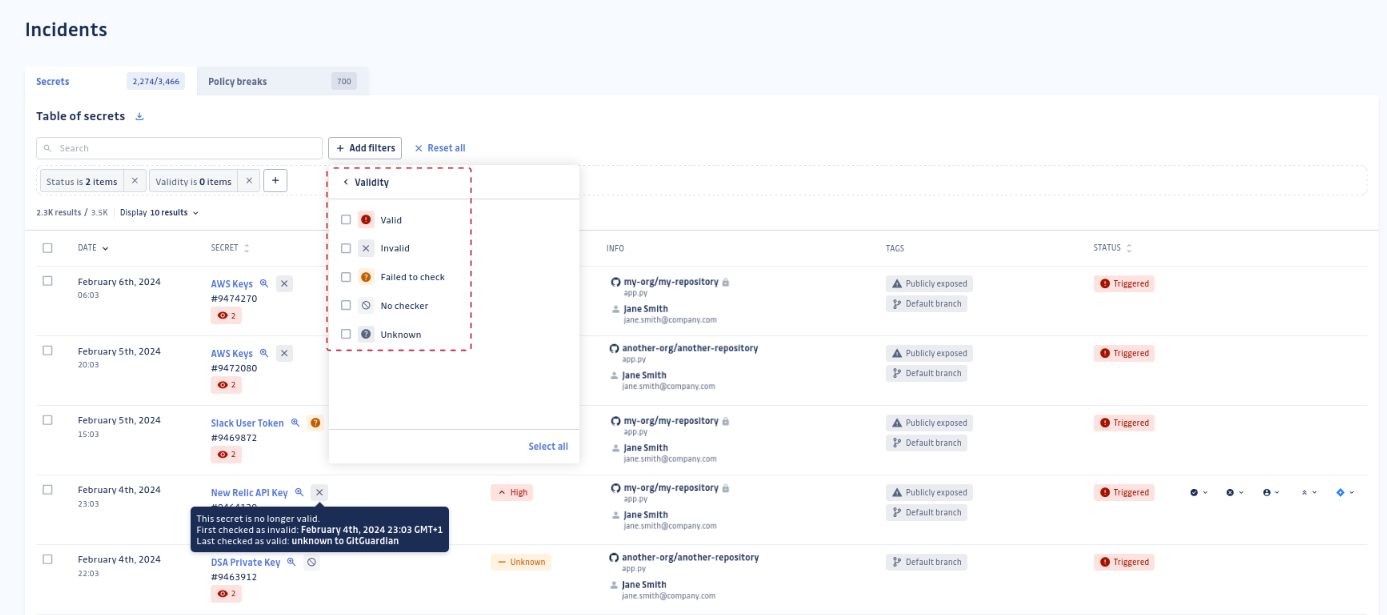
Pour plus de détails sur cette fonctionnalité, veuillez vous référer à la section dédiée sur les vérificateurs de validité.
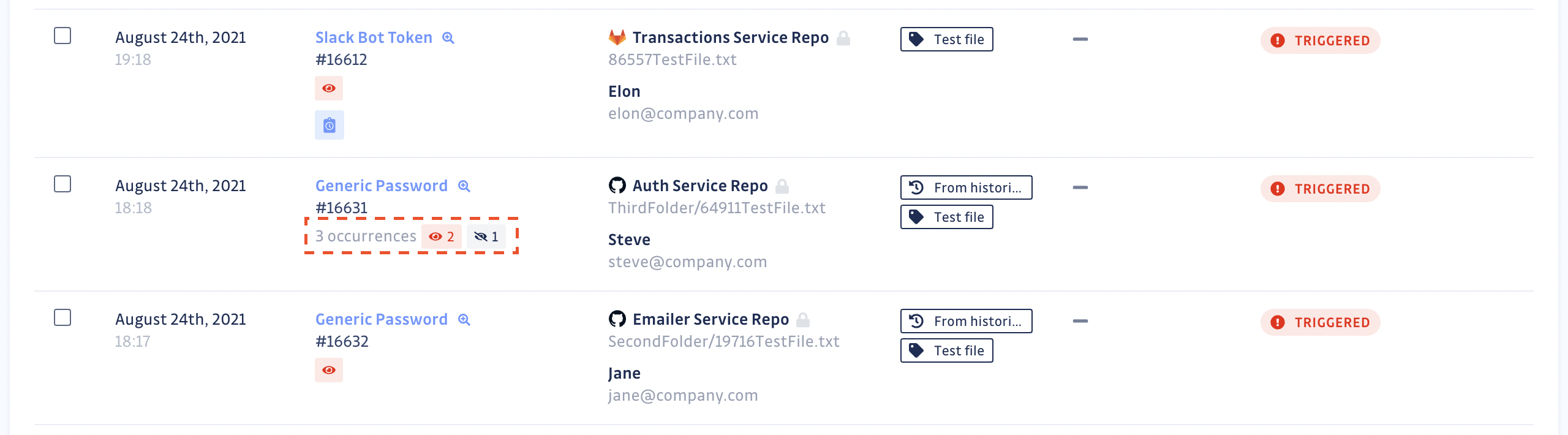
Nombre d'occurrences et présence dans l'historique git
La table d'incidents indique également le nombre d'occurrences pour chaque incident. La sévérité d'un incident ne devrait pas être déterminée simplement par son nombre d'occurrences. Cela vous informe sur la prolifération potentielle du secret mais gardez à l'esprit qu'un secret présent à plus d'un endroit n'est souvent pas un secret nuisible.
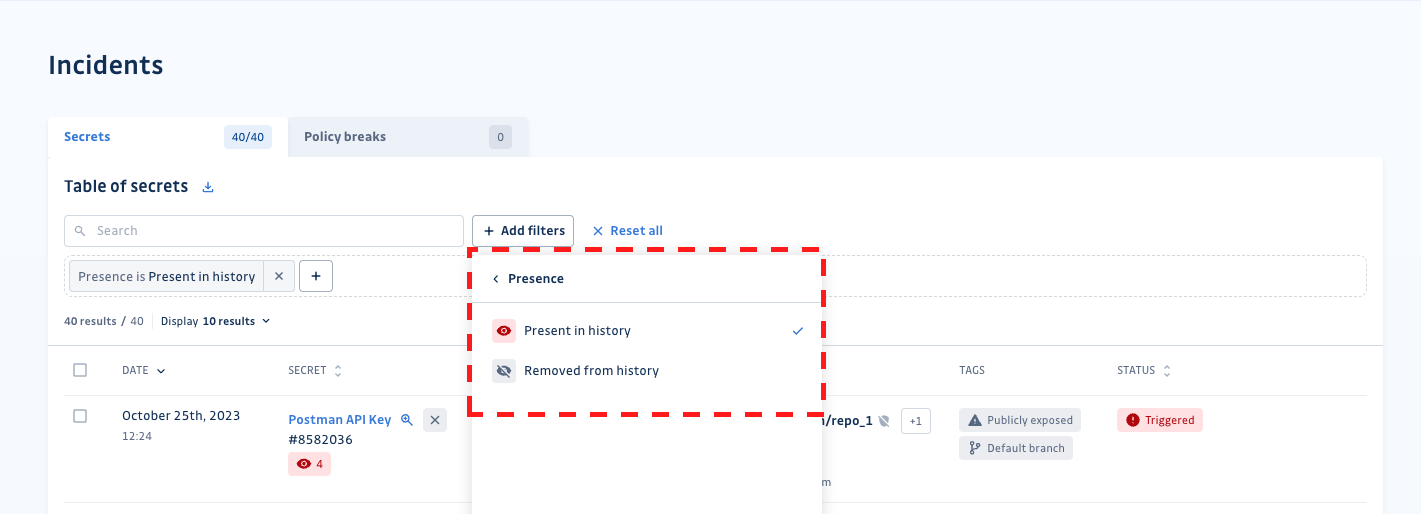
Le nombre total est divisé entre les occurrences de l'incident présentes dans votre dépôt git et celles qui ont été rendues inexistantes (suite à la suppression d'un dépôt ou à la réécriture de l'historique git).
Supprimer toute trace du secret dans vos dépôts git peut être l'une de vos exigences pour une remédiation complète d'incident. Si tel est le cas, il est possible de filtrer vos incidents pour ne voir que ceux pour lesquels au moins une occurrence est encore présente ou en d'autres termes, ceux pour lesquels la remédiation est incomplète.
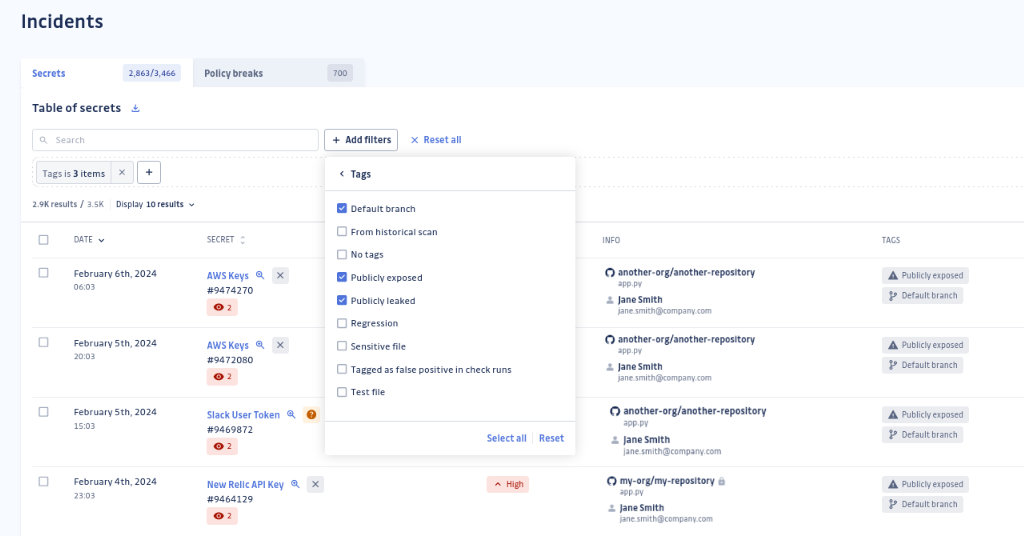
Tags GitGuardian
Pour chaque incident, nous essayons de vous fournir autant d'informations contextuelles que possible. Les tags GitGuardian sont conçus pour vous aider à évaluer rapidement chaque incident. Dans la table d'incidents, vous verrez tous les tags associés aux occurrences d'un incident. Les différents tags sont :
- Default branch : au moins une occurrence de l'incident se trouve dans la branche par défaut d'un dépôt.
- Publicly leaked : le secret a été trouvé dans un ou plusieurs emplacements publics. Ce tag indique une exposition publique et doit être priorisé pour la remédiation. Voir Informations sur l'exposition publique pour plus de détails sur les types d'exposition.
- From historical scan : l'une des occurrences de l'incident a été détectée grâce à une analyse historique, par opposition à être détectée en temps réel.
- Regression : l'incident a été résolu une fois mais GitGuardian a détecté une nouvelle occurrence.
- Sensitive file : l'une des occurrences de l'incident s'est produite sur un potentiel fichier sensible.
- Tagged as false positive in check runs : l'une des occurrences de l'incident a été taguée comme faux positif dans GitHub par l'un de vos développeurs.
- Test file : l'une des occurrences de l'incident s'est produite sur un potentiel fichier de test. Un fichier est automatiquement classé comme fichier de test si son chemin contient l'un des motifs suivants (avec uniquement des chiffres ou des caractères spéciaux autour) :
test/tests,example/examples,mock/mocks,fixture/fixtures,fake,dummy,falseoutestdata. Par exemple,.test.envou00testdata.jsoncorrespondront, maisdummydata.jsonnon. - Vaulted : le secret est stocké dans l'un de vos Secret Managers, augmentant la confiance qu'il s'agit d'un vrai positif.
- Revocable by GitGuardian : le secret peut être révoqué directement depuis le dashboard GitGuardian. En savoir plus sur la révocation.
À propos du tag Default branch. Une fois cette fonctionnalité activée sur votre workspace, le tag sera automatiquement appliqué aux futurs incidents. Pour les incidents remontés par GitGuardian avant juillet 2023, ou les dépôts où la branche par défaut a été modifiée au niveau du VCS, une analyse complète de vos dépôts doit être réexécutée.
Veuillez visiter la page perimeter pour exécuter une analyse historique.
Informations sur l'exposition publique
Lorsqu'un secret a le tag Publicly leaked, GitGuardian fournit des détails supplémentaires via la propriété Public exposure. Il existe trois types d'exposition publique :
- Source visible publiquement : l'incident a au moins une occurrence dans une source surveillée qui est visible publiquement. Cette information est disponible pour tous les utilisateurs d'Internal Monitoring.
- Possède un incident public lié : le secret apparaît également dans un ou plusieurs incidents publics du périmètre public de votre entreprise. Voir tous les détails sur les incidents publics nécessite un abonnement Public Monitoring.
- Trouvé en dehors du périmètre : le secret a été trouvé dans des emplacements publics non liés à votre entreprise (en dehors de vos périmètres internes ou publics).
Vous pouvez filtrer les incidents par type d'exposition pour concentrer vos efforts de remédiation. Pour des informations plus détaillées sur chaque type d'exposition, voir la section Informations sur l'exposition publique.
Pour les installations Self-Hosted, seul le type d'exposition "Source visible publiquement" est disponible.
Sévérité
Assignation manuelle de la sévérité
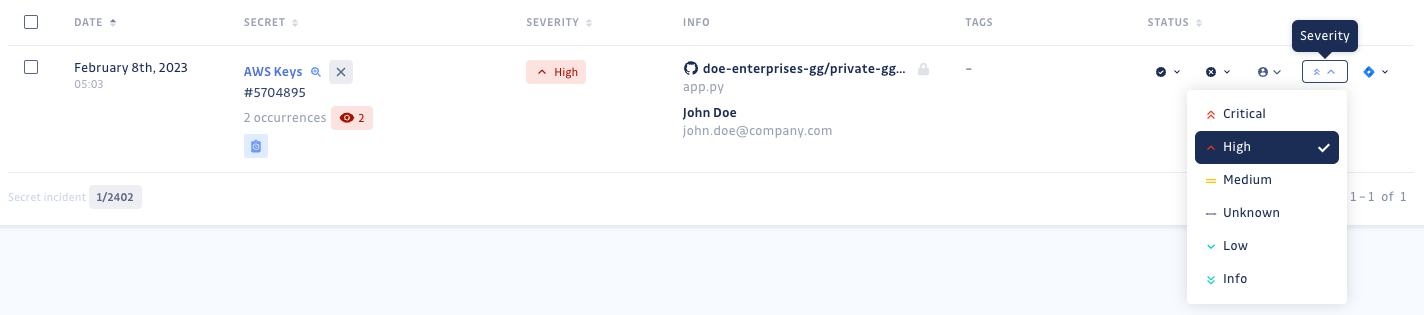
Pour vous aider à prioriser les incidents pendant le triage, vous pouvez définir une sévérité pour chaque incident. Vous pouvez définir la sévérité d'un incident soit dans sa page de remédiation dédiée, soit directement depuis la table d'incidents.
Les différents niveaux de sévérité sont :
- Critical : concerne un service critique. Doit être traité aussi rapidement que possible.
- High : concerne un service important avec un impact potentiellement large.
- Medium : concerne un service important avec un impact potentiellement limité.
- Low : concerne un service mineur avec un impact potentiellement large.
- Info : concerne un service mineur avec un impact potentiellement limité.
- Unknown : niveau par défaut appliqué par GitGuardian aux nouveaux incidents.
Scoring de sévérité automatisé
Seuls les Managers et Owners peuvent activer cette fonctionnalité.
L'assignation manuelle de la sévérité nécessite un examen au cas par cas de vos incidents ouverts et peut être chronophage pour vos équipes. La fonctionnalité de scoring de sévérité de GitGuardian automatise cette approche, où et quand applicable, aux incidents de votre workspace afin que vous puissiez gagner du temps sur leur triage et priorisation.
Le scoring de sévérité automatisé est très utile après l'exécution d'une analyse historique sur votre périmètre qui fait apparaître des centaines ou des milliers d'incidents. Il peut vous aider à concentrer vos efforts de remédiation sur les incidents les plus critiques en premier !
Pour activer la fonctionnalité de scoring de sévérité automatisé, allez à la page Severity rules dans la section Secrets de vos paramètres de workspace GitGuardian.
Vous pouvez voir la couverture du moteur de scoring de sévérité automatisé. GitGuardian le calcule en divisant le nombre total d'incidents pour lesquels il a automatiquement assigné une sévérité par le nombre total d'incidents ouverts dans votre workspace.
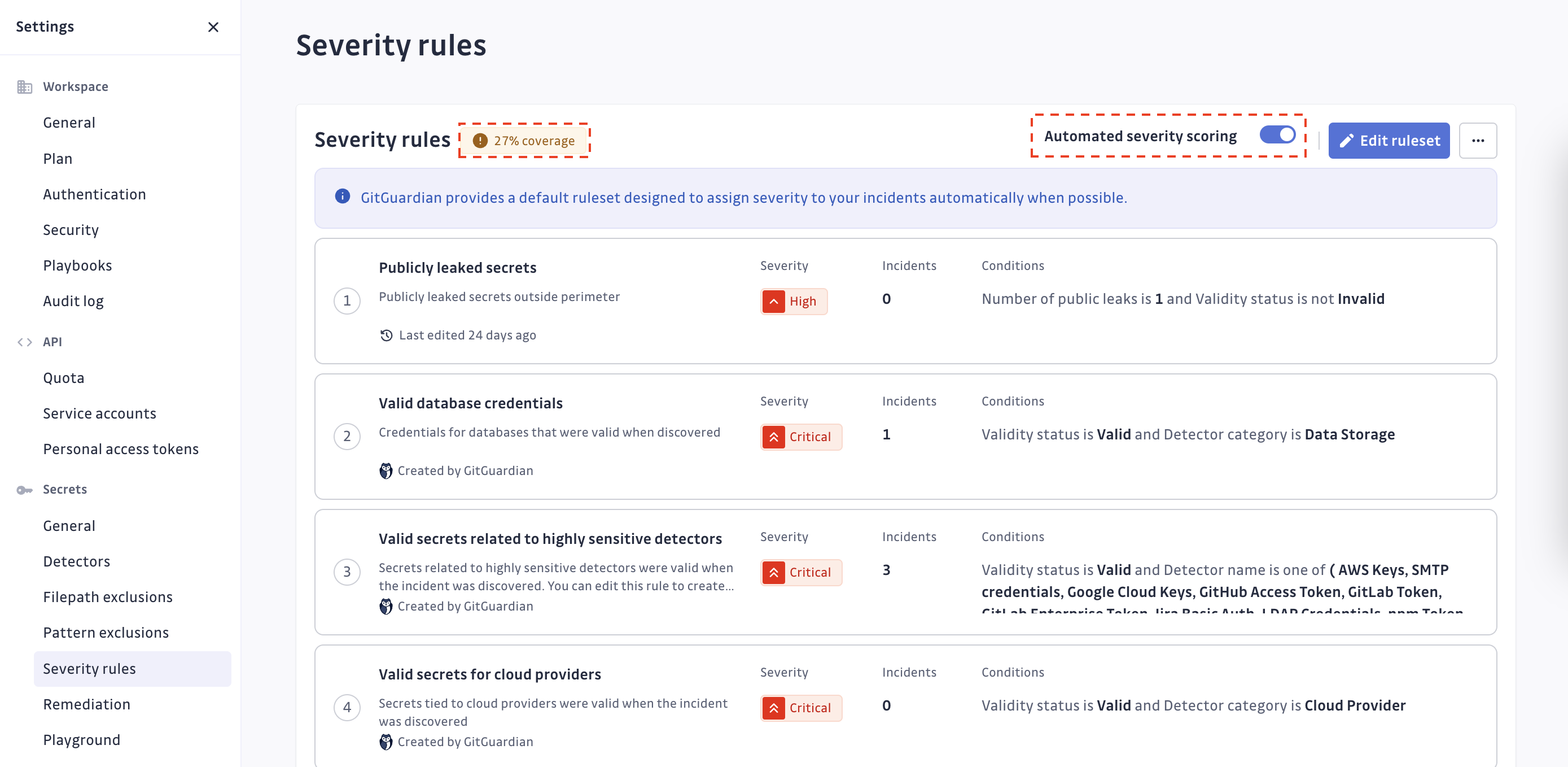
GitGuardian détermine la sévérité de chaque incident en suivant un ensemble de règles prédéfini qui peut être personnalisé. Les règles sont évaluées séquentiellement pour chaque incident de la première à la dernière. La sévérité assignée sera celle de la première règle dont les conditions sont remplies. En cas d'occurrences multiples pour un incident, le moteur de règles les évaluera toutes et assignera la sévérité la plus élevée parmi elles. Vous pouvez inspecter cet ensemble de règles dans la page Severity rules de la section Secrets de vos paramètres.
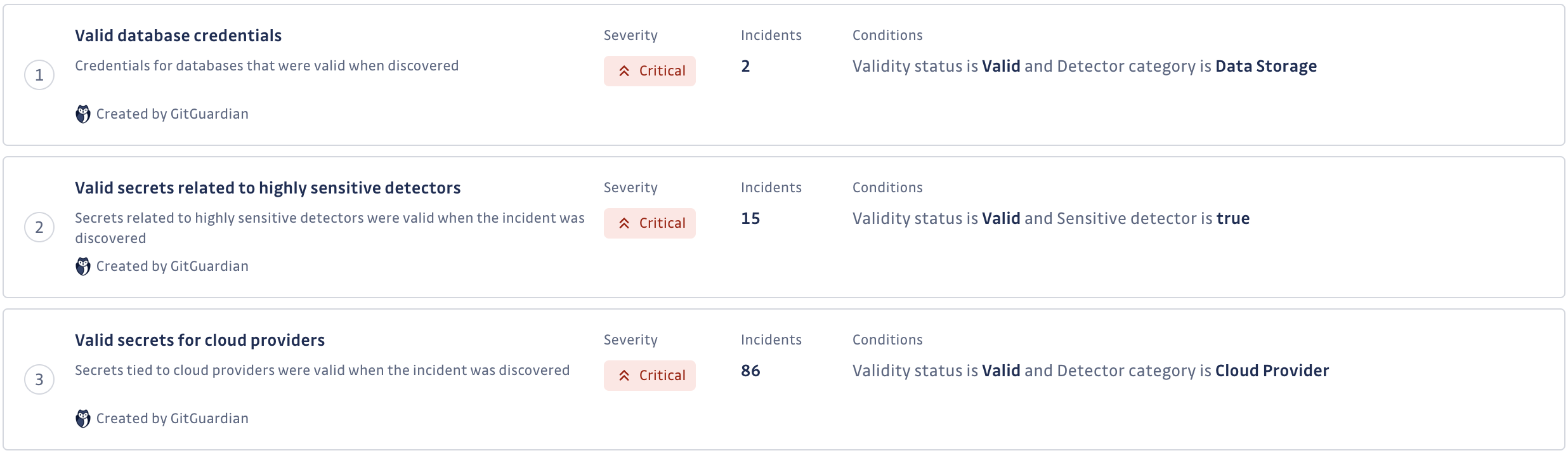
Chaque règle de l'ensemble de règles est composée des éléments suivants :
- Un nom identifiant la règle
- Une description de la règle
- Une sévérité à assigner automatiquement en cas de correspondance
- Un ensemble de conditions définissant la règle
- Le nombre total d'incidents pour lesquels la règle a défini la sévérité
En tant que Manager ou Owner du workspace, vous pouvez personnaliser cet ensemble de règles en cliquant sur le bouton Edit ruleset. Cela vous permet de maximiser la couverture des incidents scorés automatiquement en définissant un ensemble de règles lié à votre propre contexte.

L'ensemble de règles par défaut conçu par GitGuardian peut bénéficier de mises à jour régulières. Une fois personnalisé, l'ensemble de règles ne bénéficiera pas de ces mises à jour car vous devenez le manager de ces règles.
Une fois entré dans le mode d'édition de l'ensemble de règles, vous pouvez :
- Ajouter une nouvelle règle en cliquant sur le bouton
New rule(jusqu'à 20 règles) - Modifier une règle en cliquant sur l'icône stylo de la règle
- Supprimer une règle en cliquant sur l'icône poubelle de la règle (vous ne pouvez pas vider tout votre ensemble de règles)
- Réorganiser les règles en les faisant glisser les unes par rapport aux autres
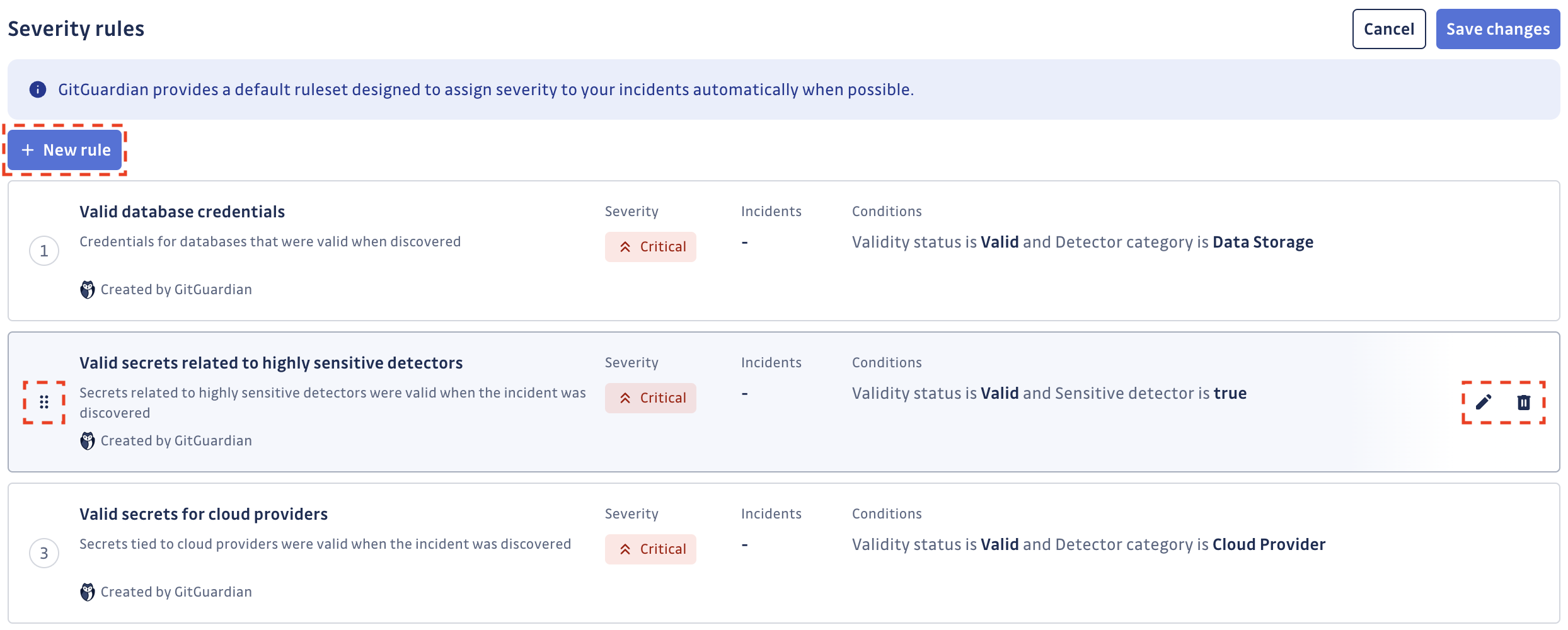
Créer ou modifier une règle vous permet de définir :
- Nom identifiant la règle
- Description de la règle (facultatif)
- Ensemble de conditions définissant la règle (jusqu'à 20 conditions)
- Sévérité à assigner automatiquement en cas de correspondance
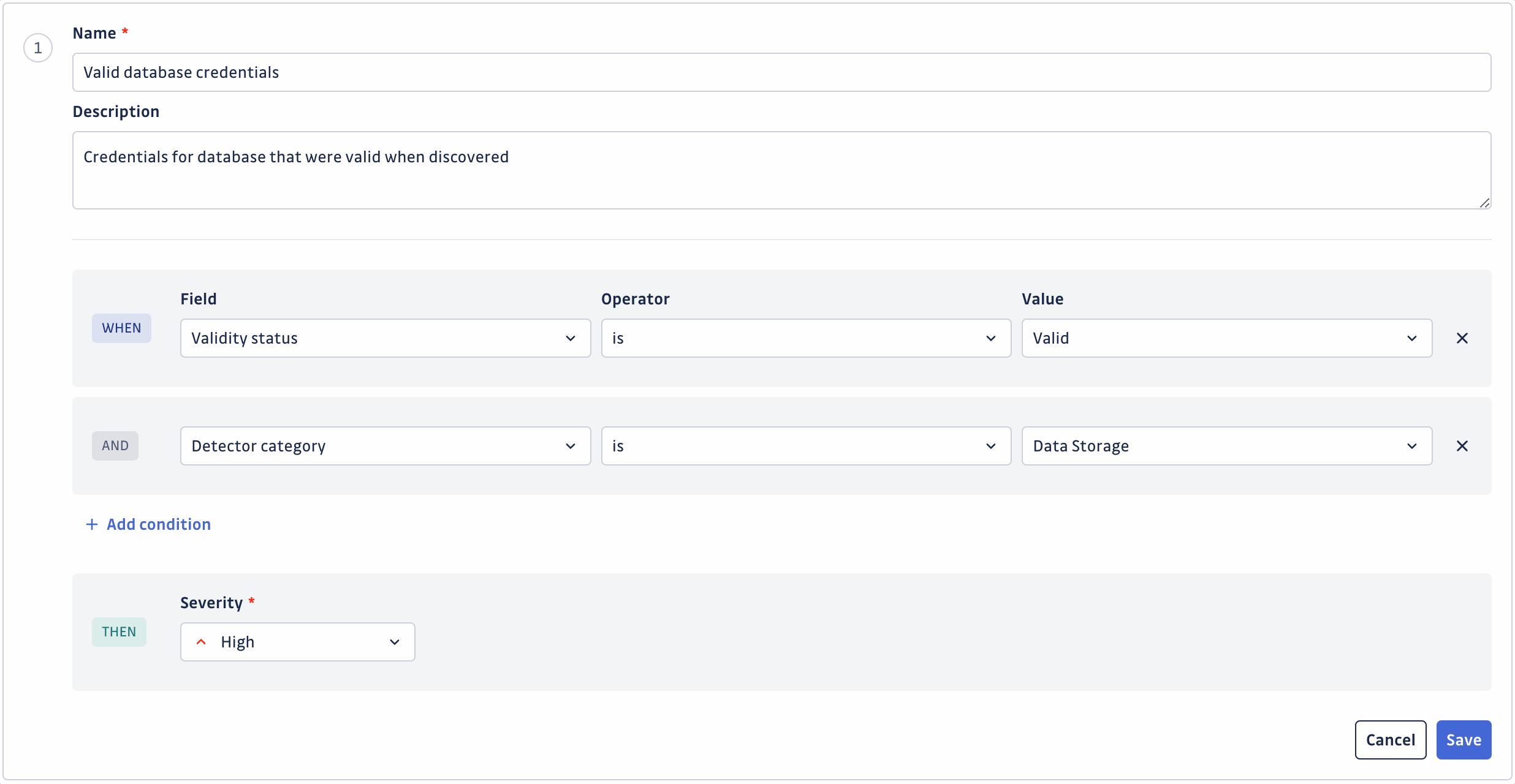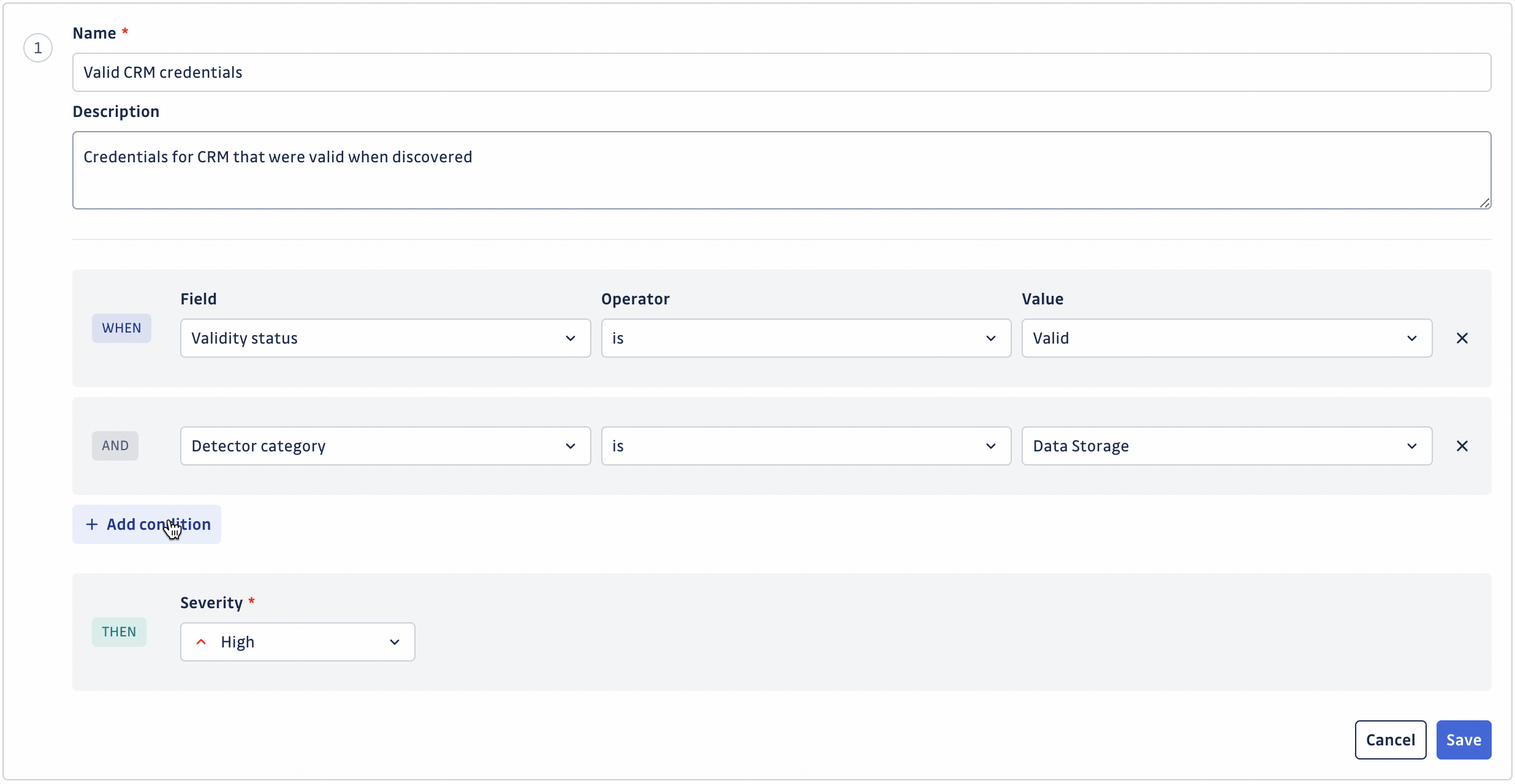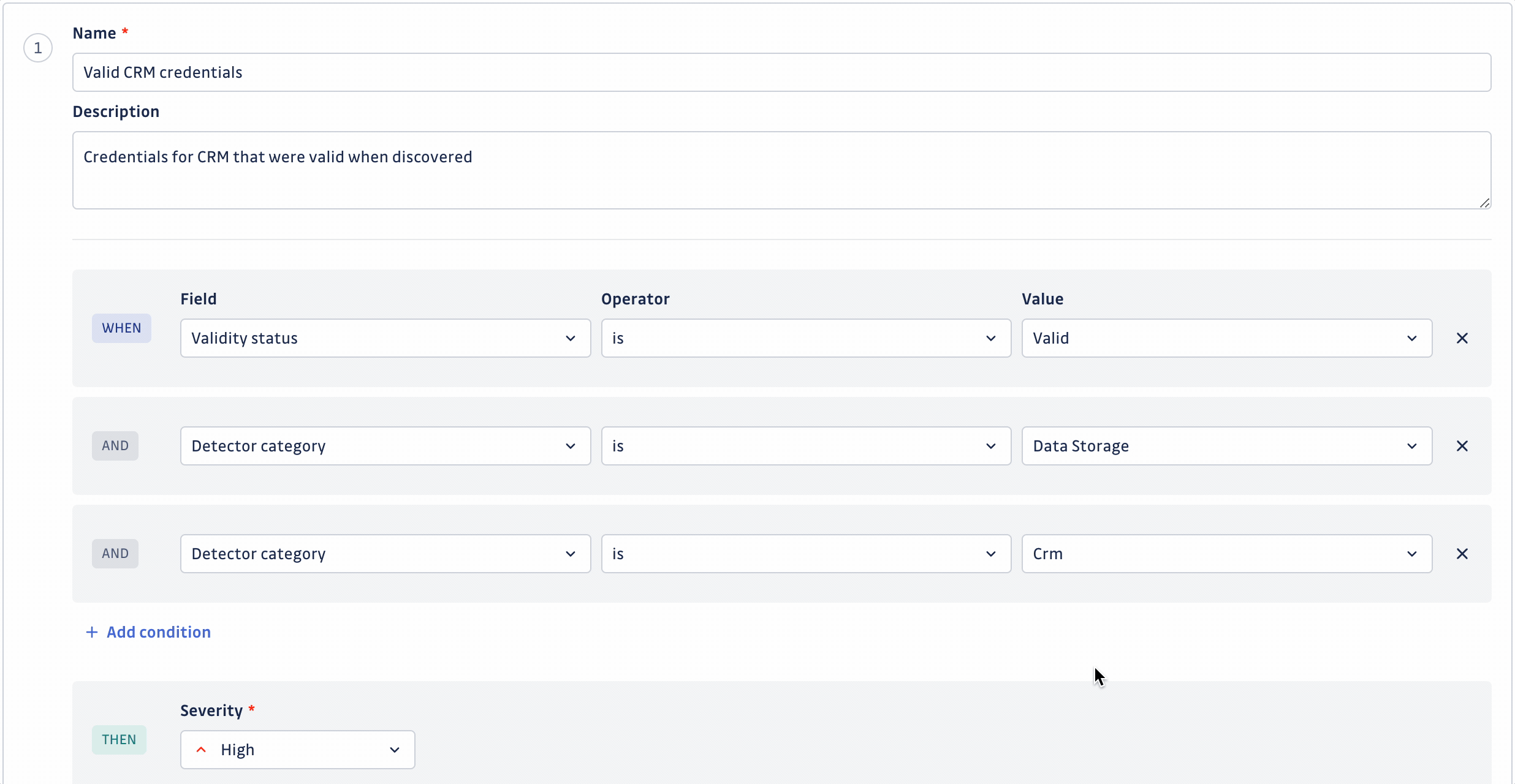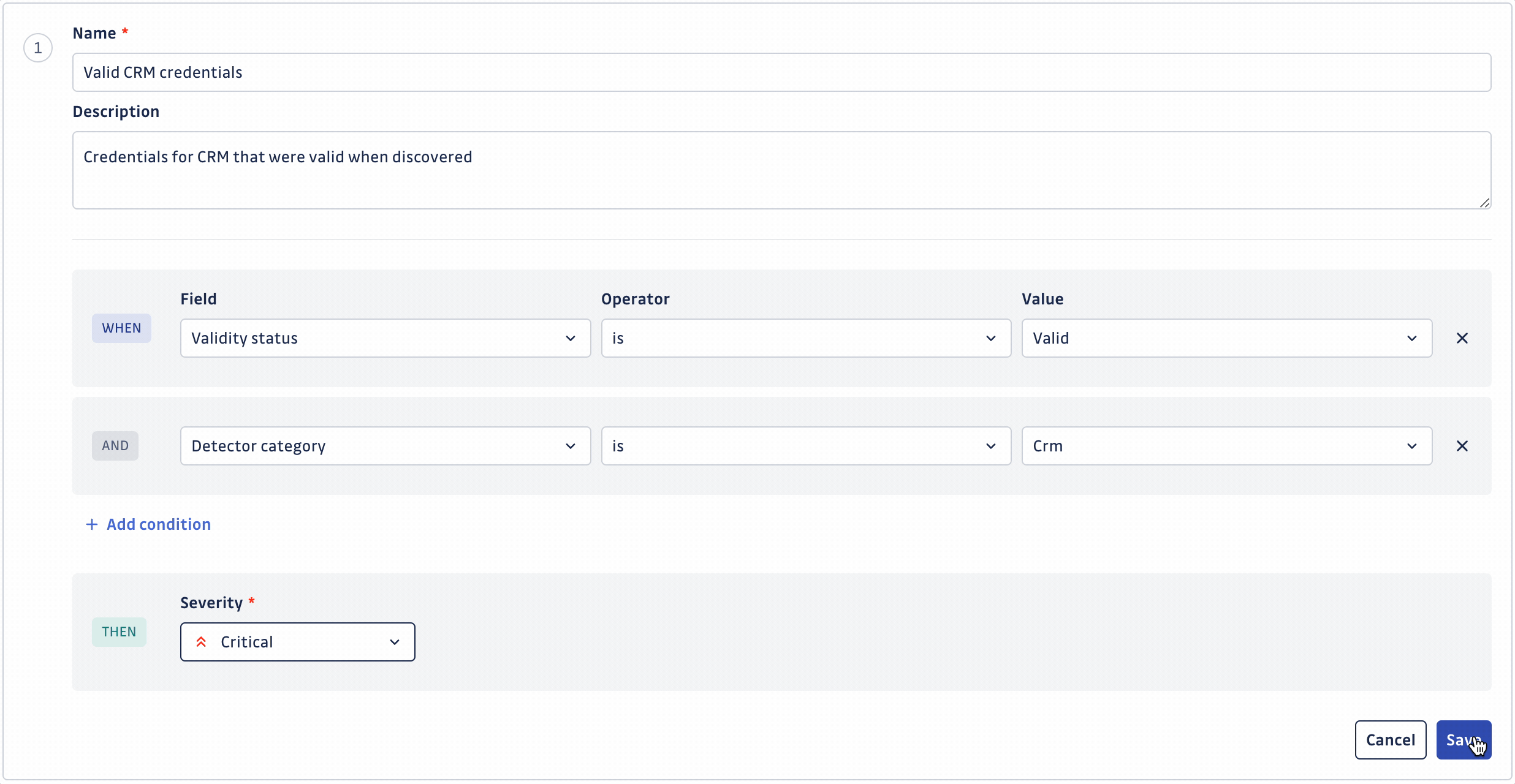
Une fois que vous avez personnalisé votre ensemble de règles, n'oubliez pas de l'enregistrer en cliquant sur le bouton Save changes. Cela entraînera un nouveau scoring de vos incidents ouverts basé sur votre nouvel ensemble de règles. Le temps de scoring dépend du nombre de vos incidents et occurrences de secrets.
Si vous le souhaitez, vous pouvez toujours réinitialiser à l'ensemble de règles par défaut défini par GitGuardian en sélectionnant l'option Reset to default dans le menu .... Cela vous permettra de bénéficier à nouveau des mises à jour de l'ensemble de règles de GitGuardian.
Vous pouvez également recalculer manuellement votre scoring de sévérité en sélectionnant l'option Recompute severity scoring.

Dans la vue de table d'incidents, survoler le badge de sévérité d'un incident affichera une infobulle indiquant si elle a été définie manuellement ou automatiquement. Dans ce dernier cas, la règle qui a correspondu sera également indiquée. Vous pouvez toujours outrepasser la sévérité automatisée définie par GitGuardian en sélectionnant une sévérité de votre choix.

Sur la page de détails d'un incident critique ou élevé, vous trouverez une bannière indiquant le score de sévérité automatisé et sa règle correspondante.
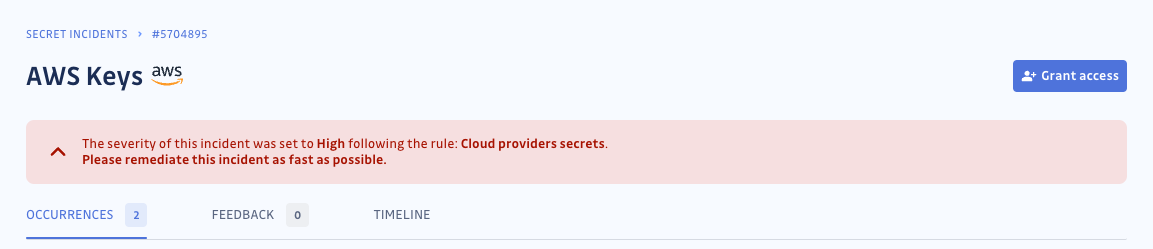
Au cas où GitGuardian ne peut pas déterminer la sévérité de l'incident, il vous en informera également dans la même bannière, et vous pouvez en assigner une directement à partir de là — en utilisant le menu déroulant.
Risk score (priorisation basée sur l'ML)
Seuls les workspaces avec un plan Business peuvent accéder au risk score.
Le risk score est une fonctionnalité basée sur l'ML qui évalue automatiquement le niveau de risque de chaque incident sur une échelle de 0 à 100, où 100 indique le risque le plus élevé nécessitant une attention immédiate et 0 indique le risque le plus faible. Il fournit une couche supplémentaire de priorisation en analysant plusieurs signaux de risque pour vous aider à vous concentrer sur les incidents qui posent la plus grande menace.
Le risk score complète le scoring de sévérité en fournissant une évaluation des risques plus granulaire et continuellement mise à jour.
Comment ça fonctionne
Le risk score est calculé en utilisant des modèles de machine learning qui prennent en compte divers facteurs notamment :
- Type de secret
- Validité (passée ou présente)
- Contexte de détection (fichiers de test, fichiers sensibles, environnement de production, etc.)
- Schémas d'exposition du secret
- Signaux contextuels supplémentaires
Le score est dynamique et se recalcule régulièrement pour refléter les changements dans le profil de risque de l'incident.
Utiliser le risk score dans votre workflow
Le risk score utilise des modèles de machine learning qui sont continuellement améliorés sur la base des retours utilisateurs. Si vous remarquez des incidents avec des scores ou des explications inattendus, nous vous encourageons à partager vos retours directement via le dashboard — votre contribution nous aide à affiner le modèle de scoring.
Dans la table d'incidents
Le risk score peut être utilisé pour prioriser les incidents de plusieurs façons :
Filtrage et tri :
- Filtrer par plage de risk score : utilisez le filtre "Risk score" pour vous concentrer sur des niveaux de risque spécifiques (par exemple, Risk score ≥ 80 pour la priorité la plus élevée)
- Trier par risk score : sélectionnez "Sort by Risk score" pour ordonner les incidents par priorité
- Utiliser la vue sauvegardée "Critical" : cette vue préconfigurée affiche tous les incidents ouverts avec un risk score supérieur à 80/100, vous donnant un accès rapide aux incidents de plus haute priorité
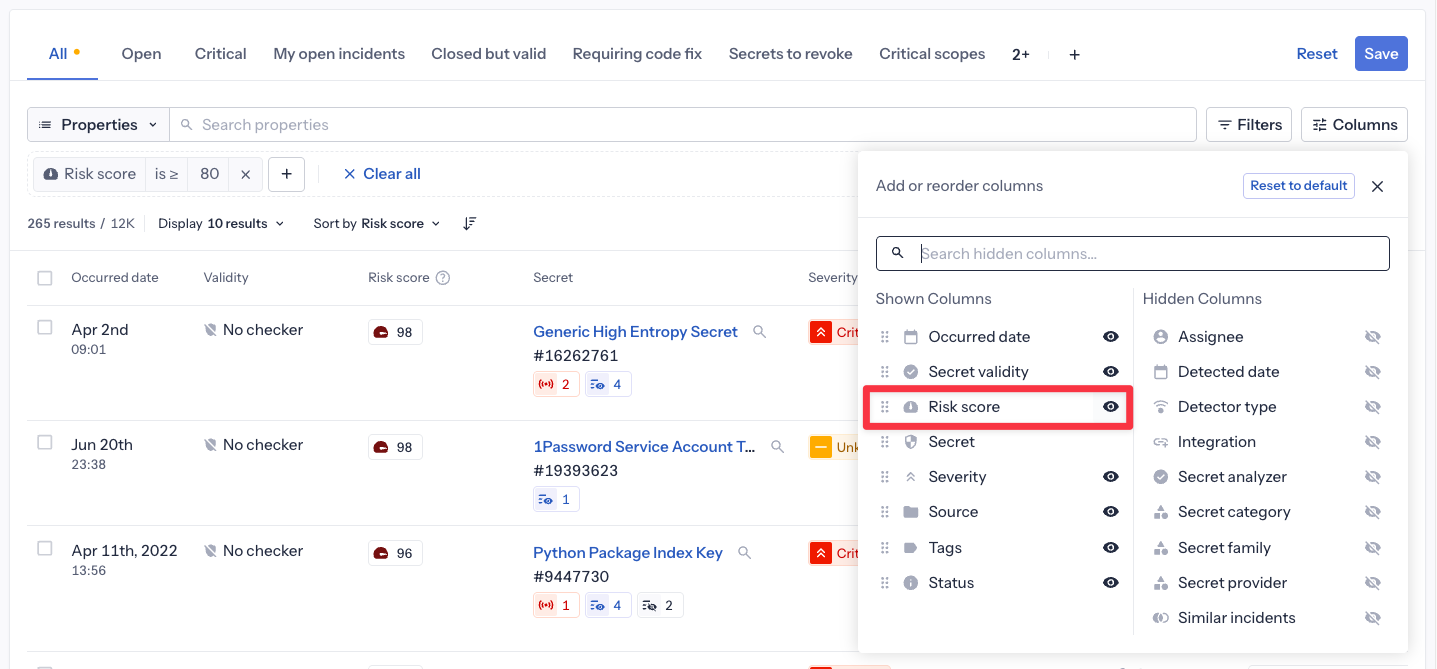
Ajouter la colonne Risk score :
Par défaut, la colonne risk score n'est pas affichée dans la table d'incidents. Pour voir les valeurs de score réelles :
- Cliquez sur le bouton Columns en haut à droite de la table d'incidents
- Trouvez "Risk score" dans la liste des colonnes disponibles
- Cliquez sur l'icône œil pour le rendre visible
- La colonne apparaîtra maintenant dans votre table, affichant le score de 0 à 100 pour chaque incident
Vue sauvegardée "Critical"
La vue sauvegardée "Critical" est préconfigurée pour afficher tous les incidents ouverts avec un risk score supérieur à 80/100. Cette vue vous aide à vous concentrer immédiatement sur les incidents qui nécessitent l'attention la plus urgente.
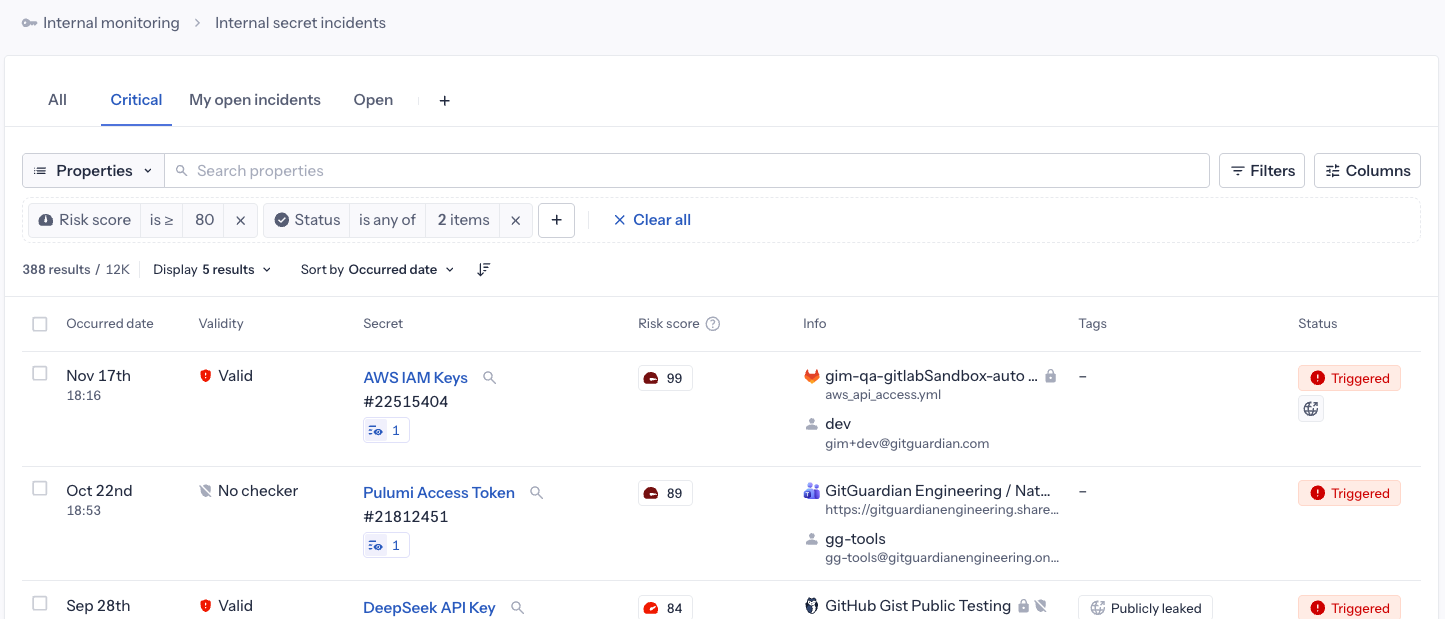
Vous pouvez dupliquer la vue sauvegardée "Critical" et ajuster le seuil de risk score pour correspondre à votre workflow. Par exemple :
- Définir un seuil plus élevé (par exemple, 90/100) pour vous concentrer sur moins d'incidents extrêmement risqués
- Définir un seuil plus bas (par exemple, 70/100) pour capturer un ensemble plus large d'incidents à examiner
Cette flexibilité vous permet de contrôler le volume d'incidents que vous souhaitez prioriser en fonction de la capacité de votre équipe et de votre tolérance au risque.
Dans la page de détail de l'incident
Lors de l'investigation d'un incident, vous trouverez le risk score en haut de la page de détail de l'incident affichant :
- Le risk score actuel (0-100) avec un indicateur visuel
- Une explication détaillée de ce qui détermine le score, basée sur le contexte et les caractéristiques de l'incident, afin que vous sachiez quoi prioriser.
- Boutons de retour pour nous aider à améliorer la fonctionnalité (pouce vers le haut/bas)
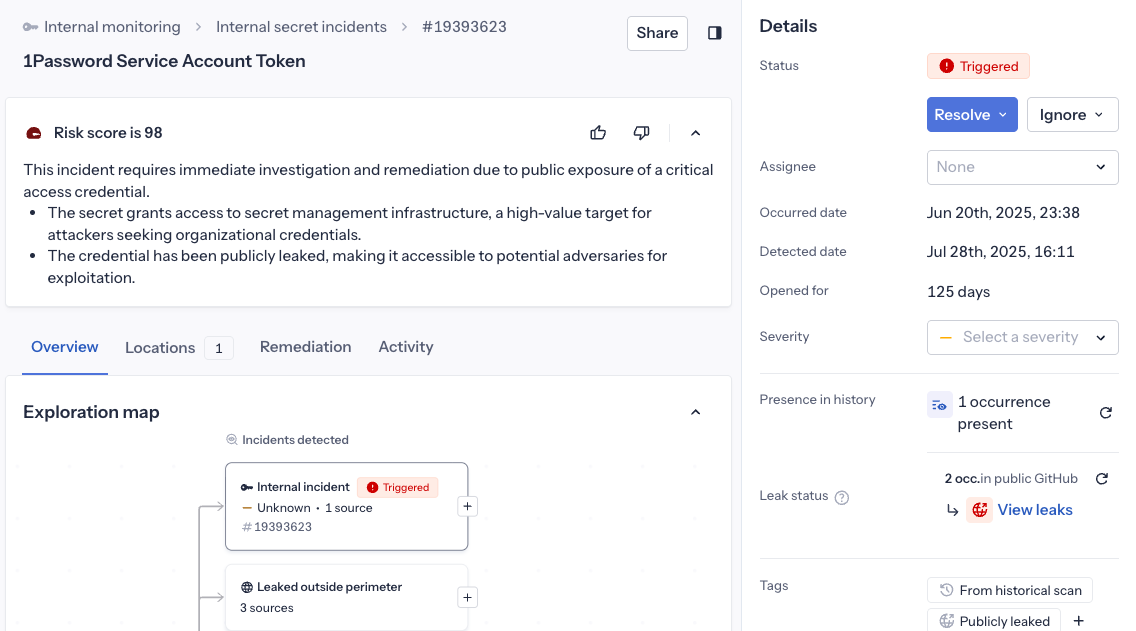
Évolution du score :
Le risk score est dynamique et se recalcule régulièrement à mesure que le contexte de l'incident évolue. Les changements dans le contexte de détection, les schémas d'exposition ou d'autres signaux de risque peuvent amener le score à s'ajuster au fil du temps. De plus, notre modèle ML est continuellement amélioré, ce qui peut conduire à des affinements de score.
Donner un retour :
Vos retours nous aident à améliorer continuellement le modèle ML. Sur la page de détail de l'incident, vous pouvez :
- Examiner le risk score et son explication
- Utiliser le bouton pouce vers le haut si le score reflète précisément le risque, ou le bouton pouce vers le bas si le score ne correspond pas à votre évaluation
- Développer/réduire l'explication à l'aide du bouton flèche
Les retours sont examinés par notre équipe pour affiner régulièrement l'algorithme de scoring.
Risk score vs Sévérité
Les deux outils aident à la priorisation mais servent des objectifs différents :
| Fonctionnalité | Risk Score | Sévérité |
|---|---|---|
| Calcul | Basé sur l'ML, automatique | Basé sur des règles, peut être manuel |
| Granularité | Échelle 0-100 | 6 niveaux (Critical à Unknown) |
| Mises à jour | Dynamique, se recalcule automatiquement | Statique sauf si modifié manuellement ou règles recalculées |
| Idéal pour | Évaluation des risques granulaire | Catégorisation basée sur les politiques |
2. Explorer avec la page d'incident
Chaque incident a une page dédiée dans laquelle vous pouvez trouver des informations supplémentaires pour vous aider à investiguer.
Vue d'ensemble du secret
La vue d'ensemble du secret fournit tous les détails relatifs au secret lui-même et les informations principales :
- le type de secret avec les informations du détecteur.
- la validité du secret si disponible.
- les valeurs du secret selon le détecteur (par exemple client_id, client_secret, etc.).
- l'analyseur de secret si disponible.
- les portées du secret si l'analyseur de secret ci-dessus est disponible et que l'analyse réussit.
Cela vous permet d'effectuer un diagnostic initial sur la criticité de cet incident.
Présence dans le Secret Manager
GitGuardian s'intègre aux Secret Managers via ggscout, vous permettant de synchroniser les incidents de secrets avec les secrets stockés dans vos Secret Managers.
Cette intégration vous permet de suivre si un secret spécifique est stocké dans un ou plusieurs Secret Managers, fournissant des insights supplémentaires tels que le chemin du secret, le temps de bail (lease time) et toute métadonnée personnalisée associée.
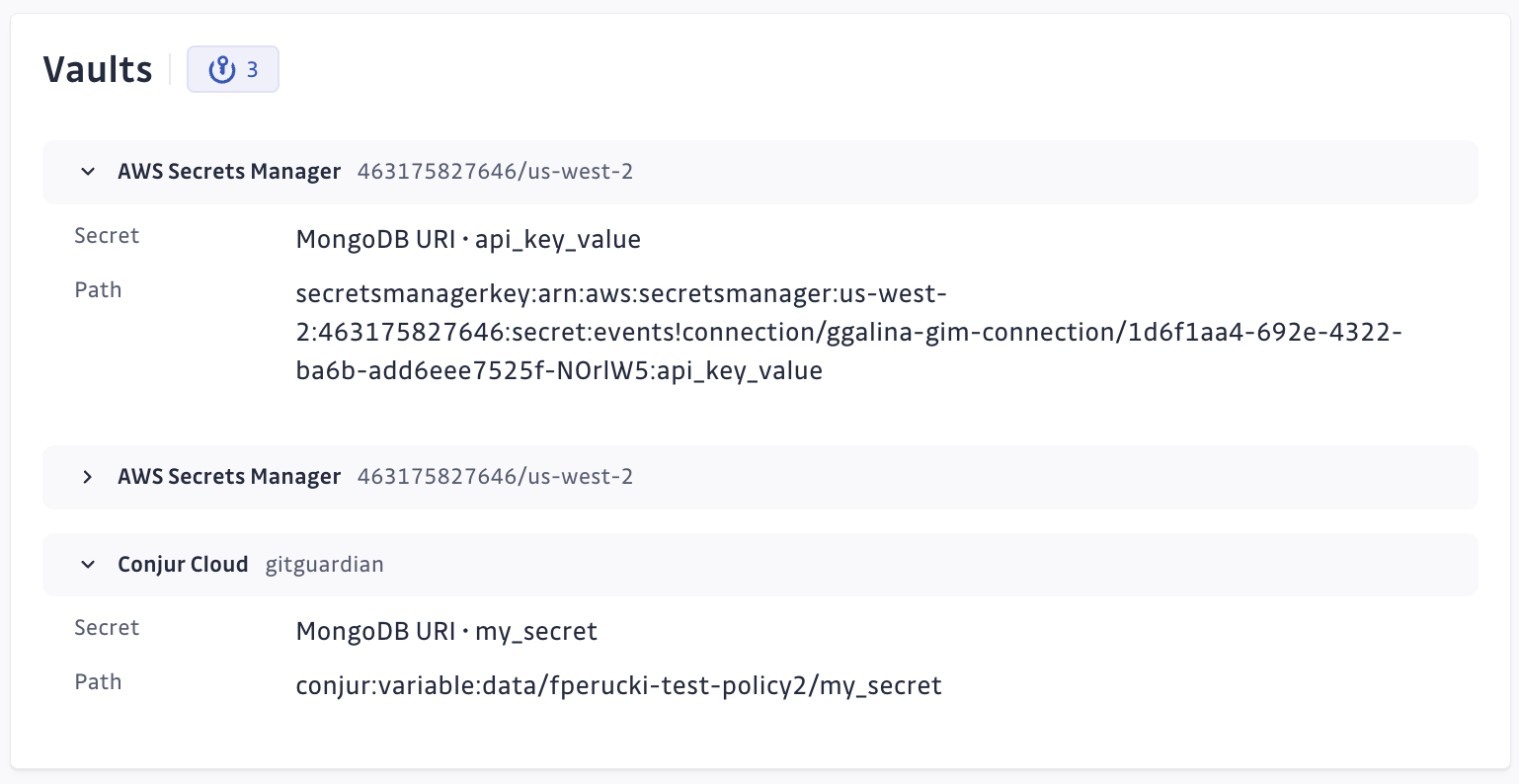
Identifier rapidement l'emplacement des secrets dans votre Secret Manager aide à gagner du temps pour vous et vos développeurs, tout en accélérant le processus de remédiation. Cela peut également aider à identifier de mauvaises pratiques de gestion de secrets, telles que la présence de secrets dupliqués.
Découvrez plus de cas d'usage dont vous pouvez bénéficier grâce aux intégrations Secrets Managers.
Périmètre impacté
La fonctionnalité Périmètre impacté répond au besoin critique d'une gestion complète des secrets dans le développement logiciel moderne. Elle fournit un aperçu rapide et une décomposition détaillée des occurrences de secrets dans votre codebase et autres sources de données, permettant aux équipes d'évaluer rapidement les vulnérabilités et de prioriser les efforts de remédiation. En suivant le statut des secrets de la détection à la remédiation, cette fonctionnalité améliore la sensibilisation à la sécurité, rationalise le processus de correction et soutient les efforts de conformité.
Le Périmètre impacté est divisé en deux sections pour obtenir soit une vue rapide soit une vue détaillée de l'impact de l'incident sur votre périmètre.
La présence du secret vous aide à avoir un aperçu du statut de l'incident dans votre périmètre en affichant les métriques suivantes :
- nécessitant une correction de code qui compte le nombre de fichiers contenant au moins une mention du secret dans le dernier commit de la branche par défaut
- le nombre d'occurrences présentes globalement ou dans d'autres sources de données
La partie Sources vulnérables liste en détail les occurrences du secret pour chaque source impactée, nécessitant ou non une correction de code.
N.B. les sources non surveillées et supprimées sont également incluses.
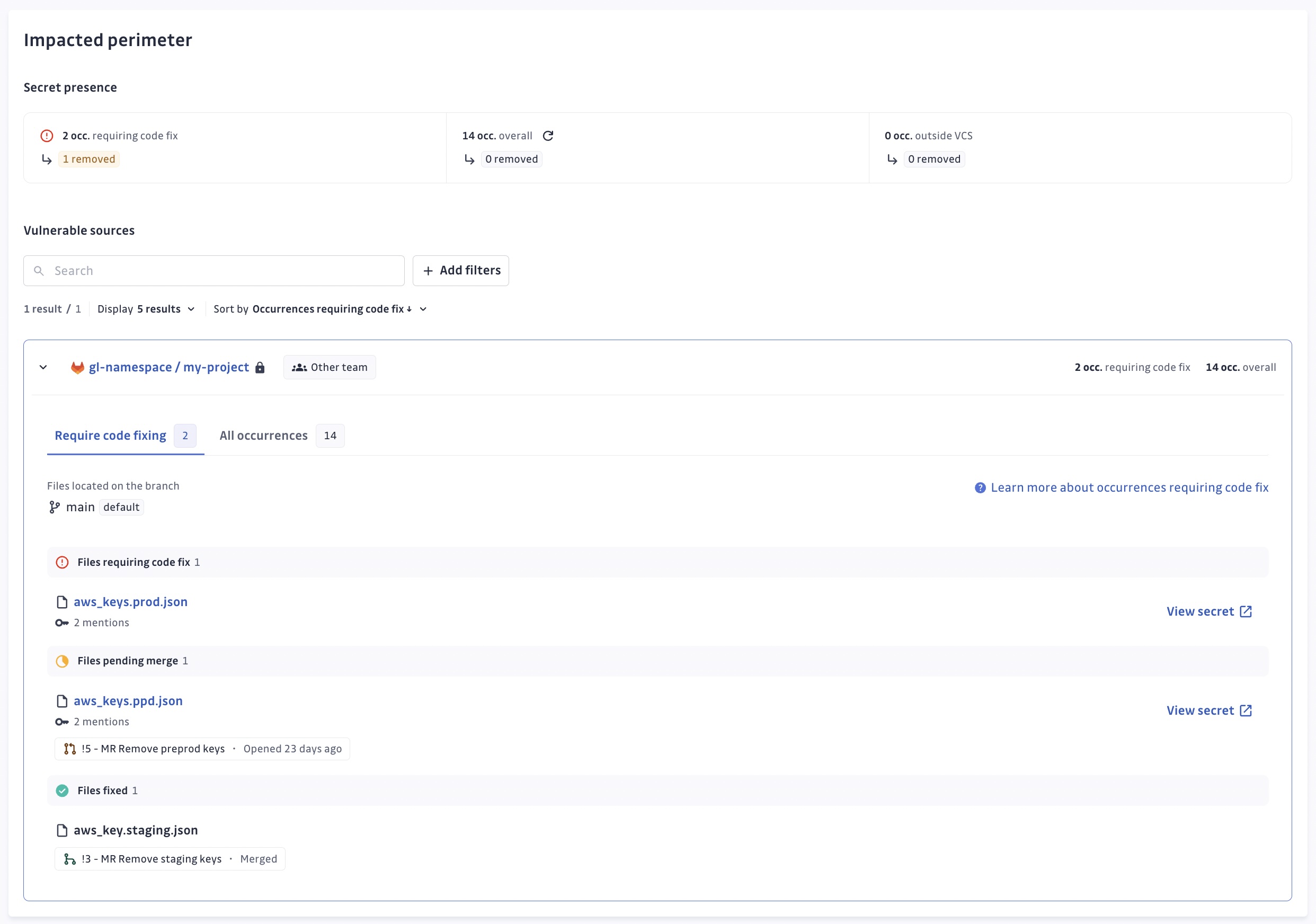
Occurrences nécessitant une correction de code
Les occurrences nécessitant une correction de code importent particulièrement car elles sont présentes dans l'état actuel du code lors de la navigation dans le VCS ou lors du clonage du dépôt. C'est l'état actuel du dépôt qui est surveillé ici. Il est possible de changer la branche par défaut surveillée en mettant à jour la branche par défaut directement dans le VCS.
Par conséquent, les fichiers vulnérables sont listés en haut dans la section fichiers nécessitant une correction de code, avec un lien vers le fichier dans le VCS.
Comme il est important de les corriger en priorité, la section fichiers en attente de merge suit la correction du code. Pour ce faire, nous surveillons les pull requests de la source et vérifions si elles sont sur le point de remédier à un incident (c'est-à-dire supprimer au moins une mention du secret), et si tel est le cas, les listons ainsi que les fichiers associés.
Une fois mergé, la pull request est listée à côté des fichiers corrigés dans la section fichiers corrigés.
Les noms des pull requests peuvent être cliqués pour les voir plus en détails sur le site web du VCS.
Limitations de la fonctionnalité :
- Le nombre de fichiers dans la PR est limité à 200 pour GitHub afin d'éviter de faire trop d'appels API ; au-dessus de cette limite, la fonctionnalité ne fonctionnera pas correctement.
- Actuellement, la fonctionnalité ne fonctionne que pour GitHub et GitLab.
Toutes les occurrences
La table des occurrences vous fournit les informations détaillées suivantes :
- quand l'occurrence s'est produite
- qui est le développeur responsable de la fuite (nom git, email git)
- où l'occurrence a eu lieu (commit, fichier)
- quand l'occurrence a été vue pour la dernière fois par GitGuardian et si elle est toujours visible dans votre historique git
- les tags associés à l'occurrence
Pour les besoins d'une investigation plus approfondie, chaque occurrence a son propre menu, avec un lien vers l'emplacement réel de l'occurrence du secret sur le VCS, si elle est encore présente.
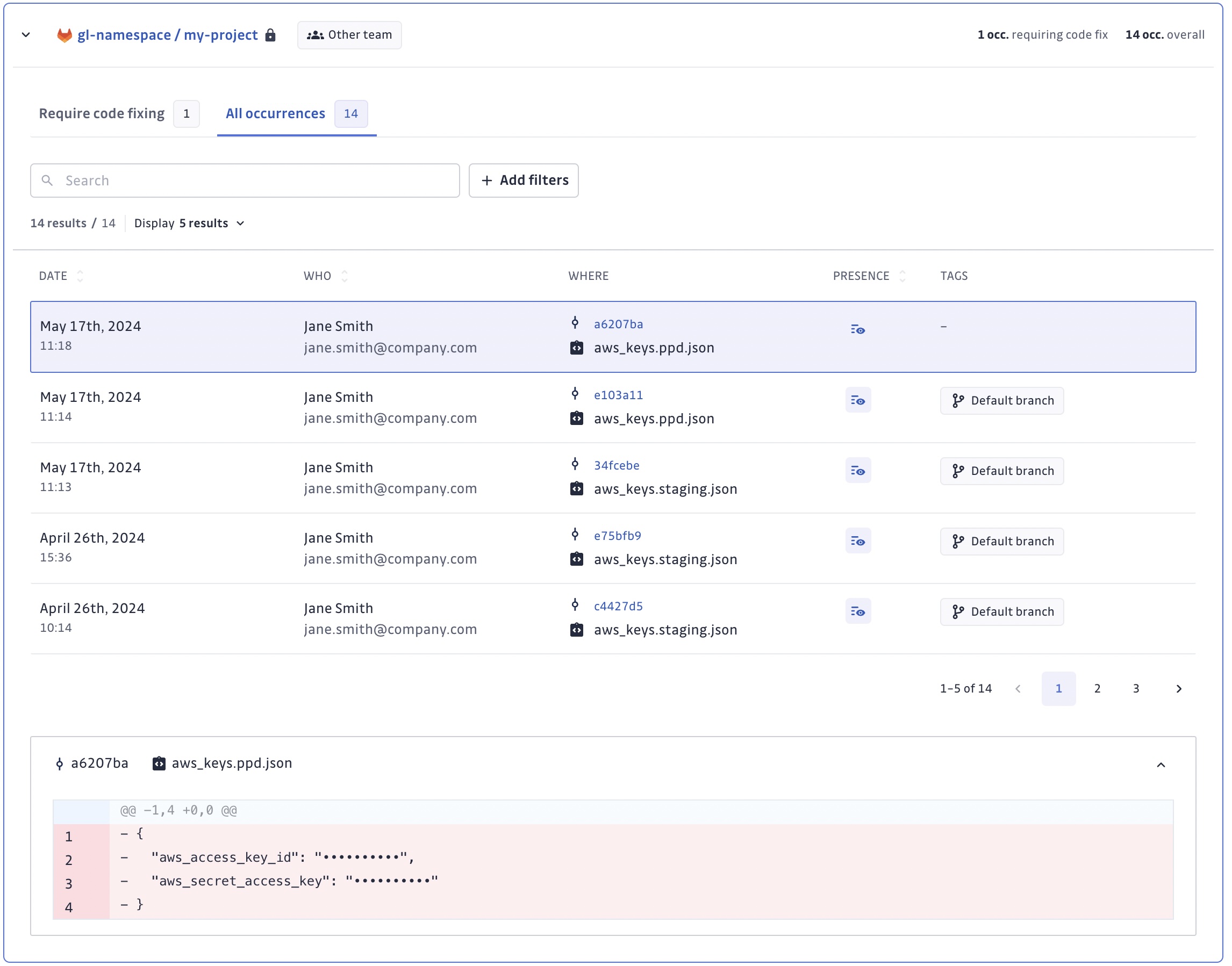
Patch
Pour chaque occurrence d'un incident de secret donné, vous avez accès au patch du commit où le secret a été détecté. Le patch est composé de :
- les lignes de code ajoutées par le commit
- les lignes de code supprimées par le commit
- les lignes contextuelles entourant les lignes ajoutées ou supprimées. Ces lignes sont également surveillées par GitGuardian car elles font partie du commit.
Un secret peut consister en plusieurs composants. Par exemple, un secret AWS est la combinaison de client_id et client_secret. Vous pouvez facilement naviguer et comprendre ces multiples composants de secret avec le patch dans votre workspace GitGuardian.

N.B. Dans la capture d'écran, le secret est obscurci car le mode privacy est activé.
D'après notre expérience, beaucoup d'informations précieuses peuvent être trouvées autour du patch d'un secret (autres secrets, données sensibles, ...).
3. Explorer les incidents génériques (modèle ML Generic Secret Enricher)
Après avoir détecté un incident générique, la plateforme analyse l'ensemble du contexte du document pour identifier le fournisseur ou la catégorie associée du secret. En cas de succès, le nom de secret enrichi remplace automatiquement le nom de détecteur générique dans toute la plateforme, transformant des découvertes vagues comme "Generic Database Assignment" en noms précis et exploitables comme "Redis Identifiers" ou "PostgreSQL Connection String".
Cette fonctionnalité est alimentée par "Secret Enricher", un modèle de machine learning spécialisé conçu pour l'analyse contextuelle des secrets. Les noms enrichis fournissent un contexte immédiat, vous permettant de comprendre rapidement quel type de secret a été exposé sans ouvrir chaque incident.
Comment l'utiliser ?
Noms enrichis dans les listes d'incidents
Les noms de secrets enrichis apparaissent automatiquement dans vos listes d'incidents — aucune configuration nécessaire. Lorsque le modèle ML identifie avec succès un type de secret, vous verrez des noms précis comme :
- Redis Identifiers au lieu de "Generic Database Assignment"
- Stripe API Key au lieu de "Generic High Entropy Secret"
- AWS Access Key au lieu de "Generic High Entropy Secret"
- PostgreSQL Connection String au lieu de "Generic Database Assignment"
Cela rend le triage des incidents plus rapide et plus intuitif, vous donnant un contexte immédiat sur ce qui a été exposé.
Personnaliser vos vues
Depuis la liste des incidents, vous pouvez personnaliser la façon dont vos incidents sont affichés en cliquant sur le bouton "Columns" dans le coin supérieur droit de la table.
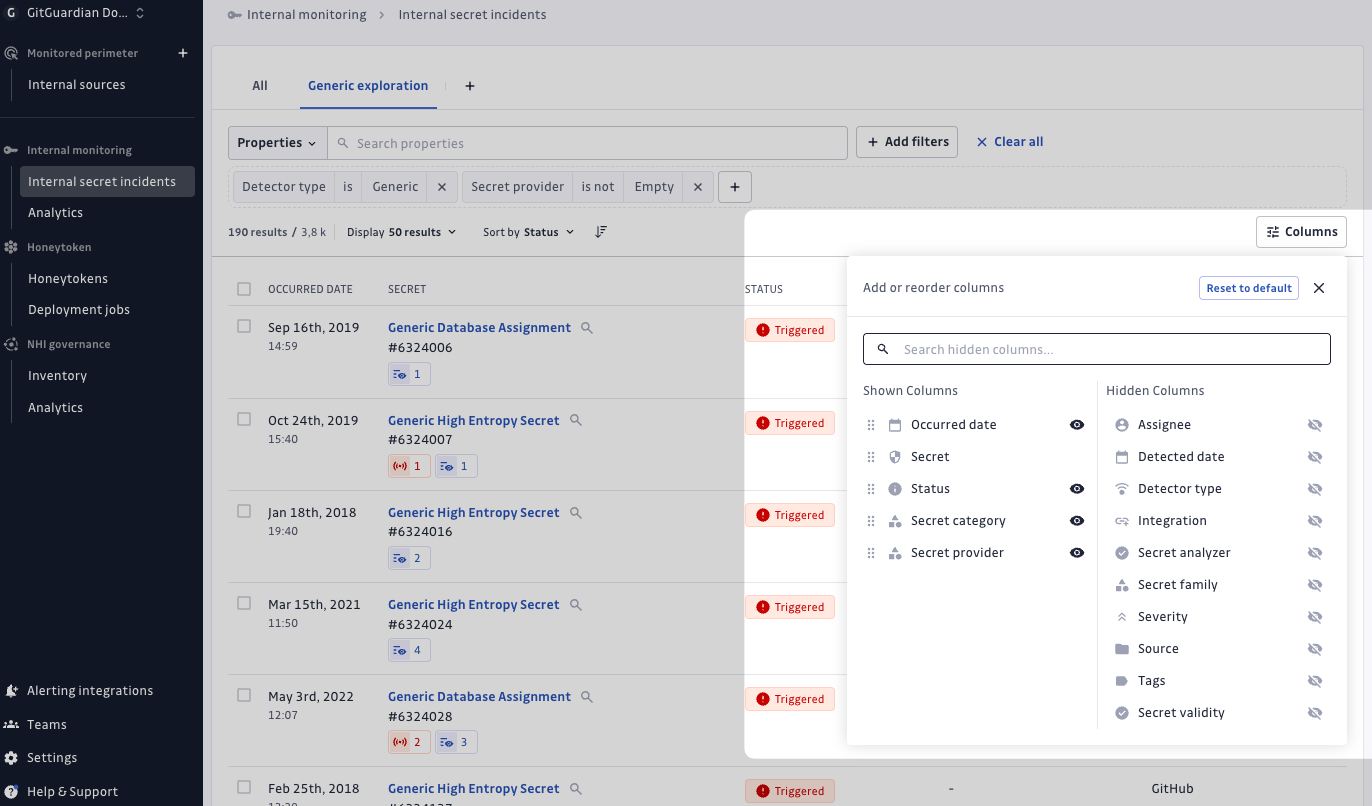
Cela vous permet d'ajouter les colonnes "Secret category" et "Secret provider", qui affichent des propriétés d'enrichissement supplémentaires aux côtés du nom de secret enrichi.
Avec cette personnalisation, vous pouvez rapidement repérer les catégories importantes (telles que "Data Storage") ou les fournisseurs spécifiques qui pourraient nécessiter une attention immédiate.
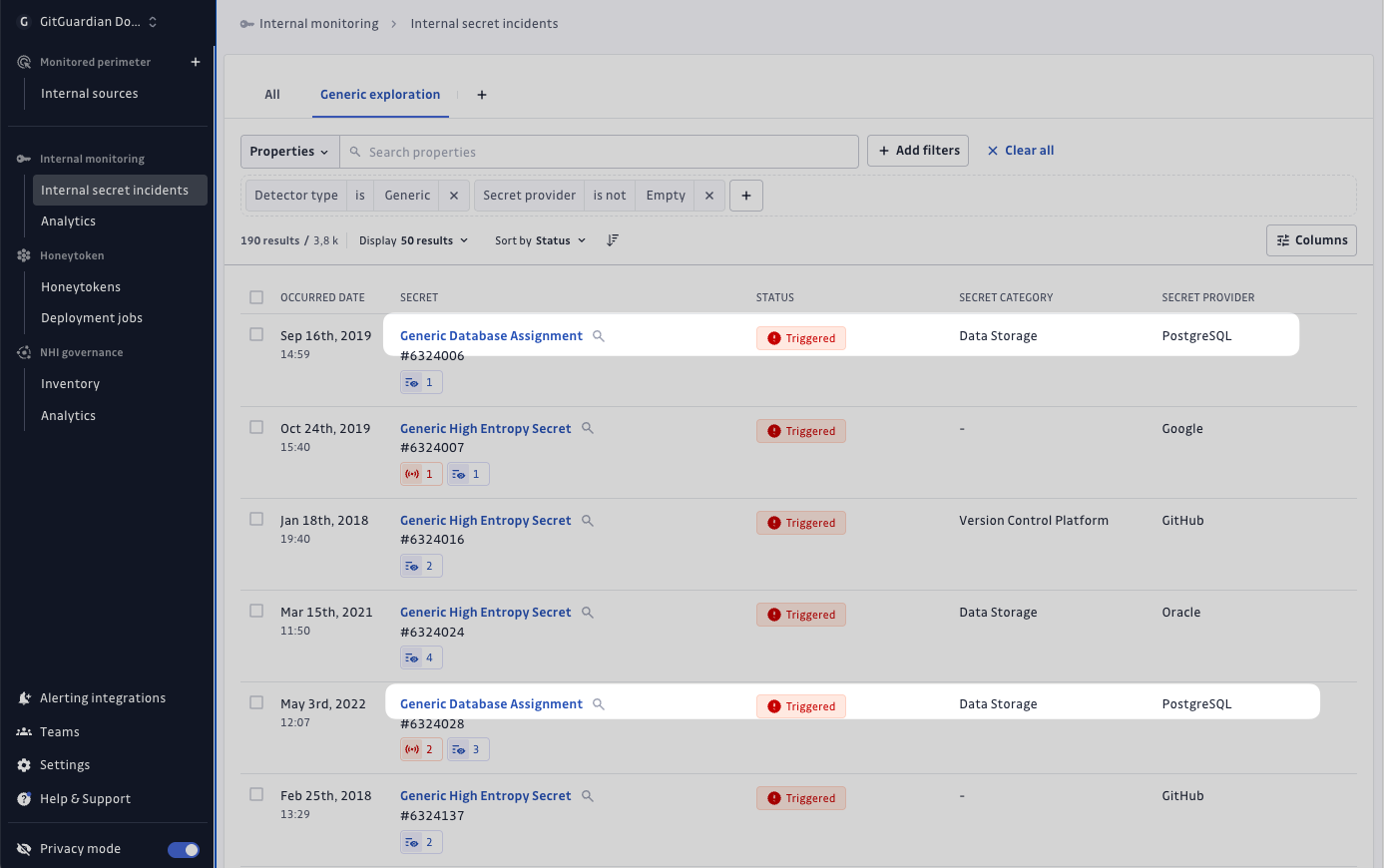
Filtrer vos données
Trois filtres (Provider, Category, Family) vous aident à identifier les incidents les plus significatifs ou critiques, tels que ceux classés sous "Data Storage" ou liés au fournisseur "PostgreSQL".
Vous pouvez appliquer ces filtres à tous les incidents enrichis ou les combiner avec le filtre de type "Generic" pour une analyse ciblée.
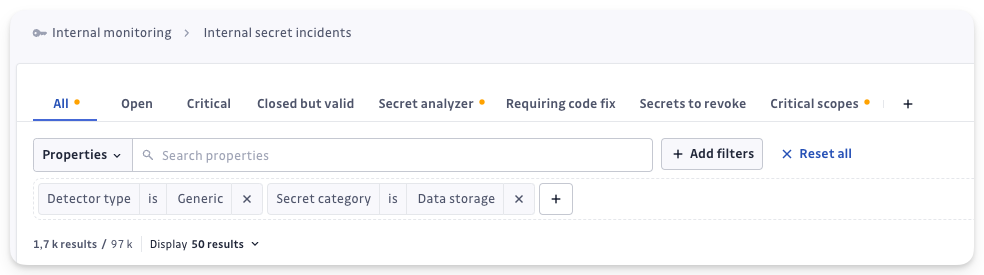
Avec ces nouveaux filtres, vous pouvez explorer vos incidents génériques et dévoiler ceux qui comptent pour vos opérations.
Pour des définitions détaillées de toutes les catégories et fournisseurs GSE, y compris ce qu'ils signifient et comment les prioriser, consultez notre Référence complète des catégories et fournisseurs GSE.
FAQ
Pourquoi ceux-ci ne sont-ils pas transformés en incidents spécifiques ?
L'analyse peut être incomplète. Nous pouvons n'être en mesure d'identifier que le Provider ou la Category (ou potentiellement aucun des deux). À mesure que nous continuons à affiner cette fonctionnalité, nos définitions deviendront plus précises.
Sur quoi le modèle est-il entraîné à découvrir ?
Pour des informations détaillées sur les catégories et fournisseurs que le modèle peut identifier, voir la documentation Machine Learning dans la section Détection de secrets.
Prochaines étapes : de la priorisation à l'investigation
Une fois que vous avez identifié et priorisé vos incidents les plus importants, vous êtes prêt à les investiguer pour une planification appropriée de la remédiation.
Ce que vous devriez avoir après la priorisation
- Une liste ciblée des incidents sur lesquels travailler en premier (sévérité élevée, secrets valides, systèmes critiques, etc.)
- Contexte sur l'urgence : quels incidents ont une exposition publique ou des privilèges élevés.
Prêt à investiguer ?
Passez à la phase d'Investigation pour :
- Comprendre ce à quoi accède chaque secret
- Évaluer l'impact d'une révocation potentielle
- Rassembler le contexte nécessaire pour une remédiation sûre
- Identifier les dépendances et les systèmes affectés
Conseil pro : même les incidents urgents bénéficient de quelques minutes d'investigation pour éviter de casser des systèmes pendant la remédiation. Utilisez la phase d'investigation pour prendre des décisions éclairées sur votre approche de remédiation.

