Métriques applicatives
Exporter les métriques de l'application vers Prometheus
Les métriques applicatives sont collectées grâce à Prometheus, un logiciel utilisé pour la surveillance d'événements et l'alerting, qui permet de scraper les données capturées dans l'application.
L'exporter Prometheus n'est pas pris en charge pour les clusters embedded.
Métriques disponibles
L'exporter Prometheus donne accès aux métriques suivantes, regroupées par domaine.
Utilisateurs et incidents
| Métrique | Type | Description | Dimensions |
|---|---|---|---|
gim_active_users_total | Gauge | Tous les utilisateurs de l'instance | Aucune |
gim_issues_total | Gauge | Tous les incidents | Severity, Status |
gim_occurrences_total | Gauge | Toutes les occurrences | Hidden, Status |
Activité de scan
| Métrique | Type | Description | Dimensions |
|---|---|---|---|
gim_commits_total | Gauge | Commits traités | Account, Scan type |
gim_repo_scan_active_statuses_total | Gauge | Compte des scans historiques | scan_feature, status |
gim_check_runs_created | Counter | Check runs GitHub créés | plan, account_id |
gim_check_runs_timed_out | Counter | Check runs GitHub qui ont expiré | plan, account_id |
gim_check_runs_runtime_bucket | Histogram | Durée des check runs GitHub | status |
gim_check_runs_error_codes | Counter | Erreurs de check run GitHub par code | error_code |
Infrastructure
| Métrique | Type | Description | Dimensions |
|---|---|---|---|
gim_postgres_used_disk_bytes | Gauge | Espace disque utilisé par PostgreSQL | Aucune |
gim_redis_used_memory_bytes | Gauge | Mémoire utilisée par Redis | Aucune |
gim_redis_available_memory_bytes | Gauge | Mémoire disponible pour Redis | Aucune |
Workers et queues Celery
| Métrique | Type | Description | Dimensions |
|---|---|---|---|
gim_celery_queue_length | Gauge | Tâches en attente dans la queue | queue_name |
gim_celery_active_consumer_count | Gauge | Consommateurs actifs dans la queue broker | queue_name |
gim_celery_worker_tasks_active | Gauge | Tâches actuellement en cours de traitement | Aucune |
gim_celery_task_sent_total | Counter | Tâches envoyées dans une queue | name, queue_name, team |
gim_celery_task_started_total | Counter | Tâches démarrées par un worker | name, queue_name, team |
gim_celery_task_succeeded_total | Counter | Tâches terminées avec succès | name, queue_name, team |
gim_celery_task_failed_total | Counter | Tâches qui ont échoué | name, exception, queue_name, team |
gim_celery_task_retried_total | Counter | Tâches retentées | name, queue_name, team |
gim_celery_task_queue_time_bucket | Histogram | Temps passé en attente dans la queue | name, queue_name, team |
gim_celery_task_runtime_bucket | Histogram | Durée d'exécution de tâche | name, queue_name, team |
Requêtes HTTP
| Métrique | Type | Description | Dimensions |
|---|---|---|---|
gim_http_request_started_total | Counter | Requêtes HTTP initiées | api, method, view_name |
gim_http_request_success_total | Counter | Requêtes HTTP réussies | api, method, view_name |
gim_http_request_failure_total | Counter | Requêtes HTTP échouées | api, method, status_code, view_name |
gim_http_request_exception_total | Counter | Requêtes HTTP ayant levé une exception | api, method, view_name, exception |
gim_http_request_view_duration_seconds | Histogram | Durée des requêtes HTTP par vue | api, method, view_name |
Health checks
| Métrique | Type | Description | Dimensions |
|---|---|---|---|
gim_health_check_result_count | Gauge | Résultats des health checks | service_name, status |
gim_outdated_health_check_count | Gauge | Health checks plus anciens que la plage périodique | service_name |
gim_health_check_skipped_total | Counter | Health checks sautés | reason, service_name |
gim_health_check_duration_metric | Histogram | Durée d'exécution des health checks | service_name |
Tâches périodiques
| Métrique | Type | Description | Dimensions |
|---|---|---|---|
gim_periodic_task_period_seconds | Gauge | Périodicité attendue d'une tâche | task_name, queue_name |
gim_periodic_task_not_run_for_seconds | Gauge | Temps depuis la dernière exécution d'une tâche | task_name, queue_name |
API publique
| Métrique | Type | Description | Dimensions |
|---|---|---|---|
gim_public_api_quota_total | Gauge | Usage maximum autorisé de l'API | Account |
gim_public_api_usage_total | Gauge | Usage actuel de l'API | Account |
gim_public_api_token_total | Gauge | Tokens API actifs | Account, Type |
Surveillance recommandée
Santé du système
| Métrique | À surveiller |
|---|---|
gim_celery_queue_length | Une croissance du backlog de queue dans le temps est le premier signe de saturation du système. |
gim_celery_active_consumer_count | Une chute du nombre de workers signale des problèmes de disponibilité. |
gim_postgres_used_disk_bytes | Surveillez la pression disque avant qu'elle ne devienne critique. |
gim_redis_used_memory_bytes / gim_redis_available_memory_bytes | Un ratio élevé indique une pression mémoire sur le cache. |
gim_periodic_task_not_run_for_seconds | Comparez à gim_periodic_task_period_seconds pour détecter les tâches bloquées. |
API et intégrations
| Métrique | À surveiller |
|---|---|
gim_http_request_failure_total | Filtrez par status_code pour repérer les pics de taux d'erreur (en particulier 5xx). |
gim_http_request_view_duration_seconds | Suivez la latence API (P95/P99) pour détecter les ralentissements. |
gim_health_check_result_count | Filtrez par status=not_ok pour détecter les intégrations cassées. |
Exemples de requêtes PromQL
# Celery queue saturation (tasks per worker)
gim_celery_queue_length / gim_celery_active_consumer_count
# HTTP 5xx error rate over the last 5 minutes
rate(gim_http_request_failure_total{status_code=~"5.."}[5m])
# API latency P95 over the last 5 minutes
histogram_quantile(0.95, rate(gim_http_request_view_duration_seconds_bucket[5m]))
# Redis memory utilization (%)
gim_redis_used_memory_bytes / (gim_redis_used_memory_bytes + gim_redis_available_memory_bytes) * 100
# Detect stalled periodic tasks (not run for 2x their expected period)
gim_periodic_task_not_run_for_seconds > 2 * gim_periodic_task_period_seconds
Exemples de règles d'alerting
Voici des règles Prometheus alerting rules de démarrage que vous pouvez adapter à votre environnement :
groups:
- name: gitguardian
rules:
- alert: CeleryQueueBacklog
expr: gim_celery_queue_length > 100
for: 5m
annotations:
summary: "Queue {{ $labels.queue_name }} has {{ $value }} pending tasks"
- alert: RedisMemoryPressure
expr: >
gim_redis_used_memory_bytes
/ (gim_redis_used_memory_bytes + gim_redis_available_memory_bytes) > 0.85
for: 10m
- alert: PeriodicTaskStalled
expr: gim_periodic_task_not_run_for_seconds > 2 * gim_periodic_task_period_seconds
for: 5m
- alert: HighHTTPErrorRate
expr: rate(gim_http_request_failure_total{status_code=~"5.."}[5m]) > 0.1
for: 5m
Visualiser les métriques avec Grafana
GitGuardian ne fournit pas de dashboards Grafana pré-construits, mais toutes les métriques gim_* sont des métriques Prometheus standards et fonctionnent avec n'importe quelle instance Grafana connectée à votre serveur Prometheus.
Pour démarrer :
- Ajoutez votre serveur Prometheus comme data source Grafana.
- Créez des panels en utilisant les requêtes PromQL ci-dessus.
- Organisez les panels en lignes : Santé du système (queues, Redis, Postgres, tâches périodiques) et API & Intégrations (taux d'erreur, health checks).
Activer ou désactiver les métriques applicatives
Les métriques applicatives sont désactivées par défaut. Deux étapes sont nécessaires pour activer les métriques applicatives :
- autoriser la collecte des métriques par l'application
- activer l'export Prometheus
Autoriser la collecte des métriques
Pour autoriser la collecte des métriques, allez dans la section Préférences
de l'Admin Area, cochez le feature flag prometheus_metrics_active et
enregistrez les paramètres.
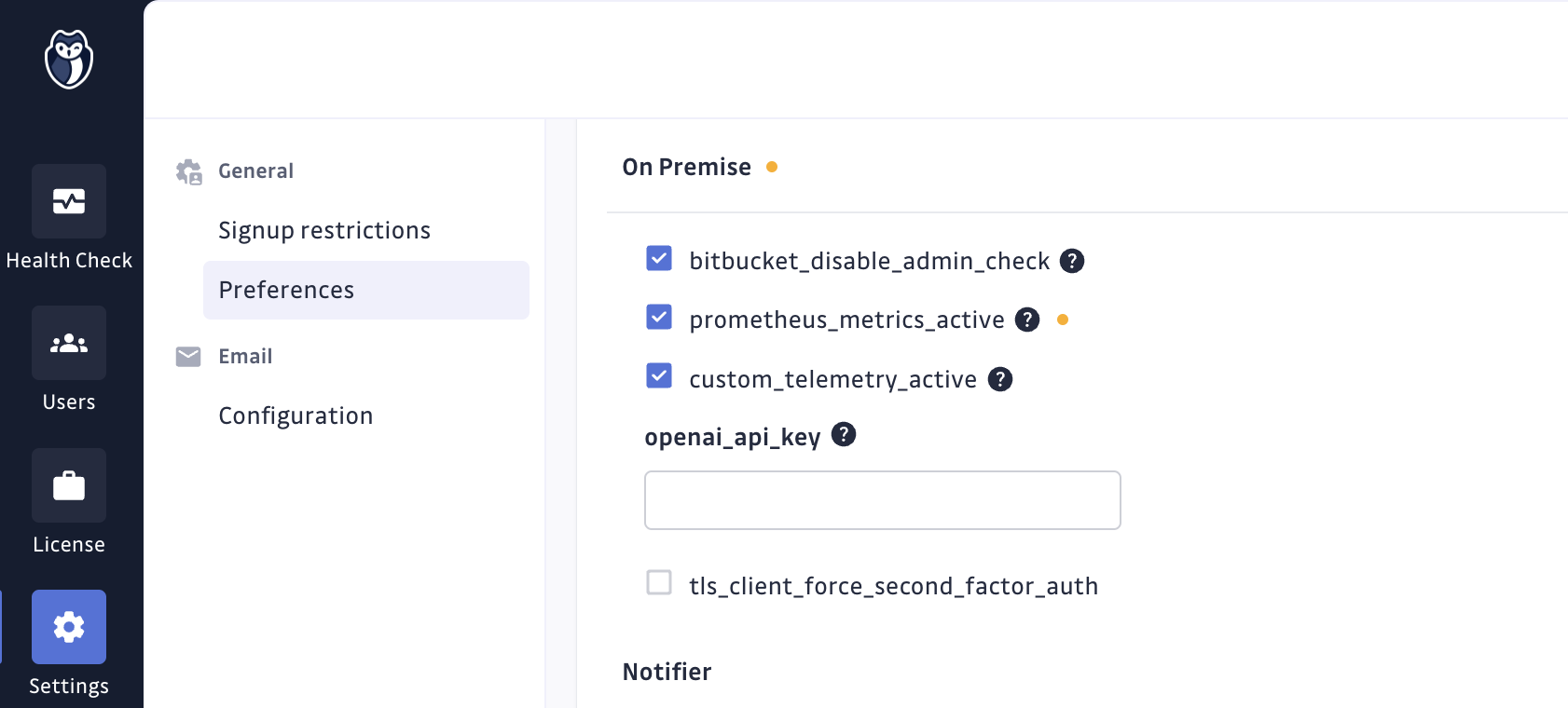
Pour la désactiver, décochez ce paramètre et enregistrez les paramètres.
Installer Prometheus Operator
Les métriques sont collectées par Prometheus en utilisant le Prometheus Operator.
Pour les clusters existants, vous devez l'installer manuellement (documentation d'installation).
Activer l'export Prometheus via KOTS
Pour créer les ressources d'export et permettre la découverte automatique, allez dans la console d'administration KOTS et cochez la case Activate Prometheus Exporter dans la section Prometheus de la section configuration.

Puis enregistrez la configuration et Déployez l'application pour appliquer la nouvelle configuration.
Pour la désactiver, décochez ce paramètre, enregistrez la configuration et appliquez-la via un nouveau déploiement.
Activer l'export Prometheus via Helm
L'exporter de métriques applicatives peut être activé en définissant observability.exporters.webAppExporter.enabled=true dans le fichier de values.
observability:
exporters:
webAppExporter:
enabled: true
Notez que l'application Helm dispose aussi d'un Celery Exporter permettant de surveiller plusieurs métriques Celery comme « count of active tasks by queue ». La liste complète des métriques est disponible ici.
Vous pouvez activer Celery Exporter dans votre fichier de values :
observability:
exporters:
webAppExporter:
enabled: true
statefulAppExporter:
enabled: true
Si vous utilisez Prometheus Operator, vous pouvez vouloir utiliser le Service Monitor fourni pour la découverte automatique de l'exporter par Prometheus :
observability:
exporters:
webAppExporter:
enabled: true
statefulAppExporter:
enabled: true
serviceMonitors:
enabled: true
Sinon, vous pouvez scraper manuellement les exporters.
- Les métriques applicatives peuvent être scrapées depuis le service app-exporter à :
http://app-exporter:9808/metrics - Les métriques Celery peuvent être scrapées depuis le service celery-exporter à :
http://celery-exporter:9808/metrics
Comment collecter les métriques
Sur les clusters existants, Prometheus doit être installé et configuré manuellement. Si l'opérateur Kube-Prometheus est utilisé, toutes les métriques applicatives seront automatiquement listées grâce au service Discovery de Kube-Prometheus Operator.
Sinon, une configuration manuelle peut être nécessaire.
La découverte des métriques applicatives est possible via le service headless app-monitoring.
Ce service expose un pod exporter servant les métriques sur http://exporter-xxxxx-xxxxx:9808/metrics
Données d'usage
GitGuardian collecte des données d'usage pour améliorer l'expérience utilisateur et le support. Cela peut être facilement désactivé en
ajustant le paramètre custom_telemetry_active trouvé dans la section préférences
de l'Admin area.
Pourquoi garder les données d'usage activées ?
-
Amélioration continue du produit : les données d'usage nous aident grandement à comprendre comment notre application est utilisée dans divers environnements. Cela nous permet de cibler spécifiquement les zones nécessitant des améliorations et de diriger nos efforts de tests. Cela garantit que notre produit évolue pour répondre efficacement aux besoins de nos utilisateurs tout en contribuant à une meilleure qualité et stabilité.
-
Support ciblé et efficace : en cas de problèmes techniques, les données d'usage permettent à GitGuardian d'identifier et résoudre les problèmes beaucoup plus rapidement. Cela signifie une indisponibilité réduite pour vous et une meilleure expérience utilisateur globale.
-
Sécurité et confidentialité : nous voulons vous rassurer que la confidentialité et la sécurité des données sont notre priorité absolue. Nous ne collectons aucune donnée personnelle ou sensible. Notre objectif est uniquement d'améliorer l'expérience utilisateur et les performances de notre produit.
Voici les catégories et métriques que nous collectons :
-
Replicated
- Diverses métriques liées au déploiement comme le statut cloud, la version et l'uptime
-
Système
- Fournisseur SSO
- Type de Network Gateway
- Statut Custom CA et proxy
- Statut d'activation des métriques applicatives Prometheus
-
Utilisateurs & Teams
- Nombre d'invités en attente, d'utilisateurs enregistrés avec différents niveaux d'accès, d'utilisateurs actifs.
-
Scan historique
- Nombre de scans historiques annulés, échoués et terminés
- Durées en percentile des scans historiques
- Nombre de secrets trouvés par jour et de scans de sources par jour dans les scans historiques
- Nombre de scans historiques considérés comme trop volumineux
-
Intégrations
- Nombre d'instances, installations, projets, sites pour les VCS et autres sources de données
- Nombre de sources surveillées et non surveillées, avec percentiles de taille de source et utilisateurs estimés par VCS
-
Secret
- Nombre de détecteurs désactivés par catégorie, retours enregistrés et non enregistrés, et diverses métriques liées aux vérifications de validité de secrets et incidents
-
API publique
- Nombre d'appels pour les scans de secrets ggshield, incluant différents modes et dépôts
- Nombre de personal access tokens et service accounts actifs
- Nombre d'appels à l'API publique

