Machine Learning
Cette section décrit les fonctionnalités de machine learning implémentées dans GitGuardian, détaillant comment elles fonctionnent et comment les activer en Self-Hosted. Une fois activées, vous pouvez enrichir les incidents passés avec l'analyse machine learning.
Pour plus de détails sur les capacités machine learning, consultez la documentation Machine Learning Secret Detection.
Prérequis système
Le ML Secret Engine nécessite 3 vCPU et 2,5 Gio de RAM par réplica. Pour des directives de scaling détaillées, des métriques de performance et des recommandations d'infrastructure, consultez la documentation Scaling.
À partir de la version 2025.7.0, le Machine Learning est activé par défaut.
Installation via KOTS
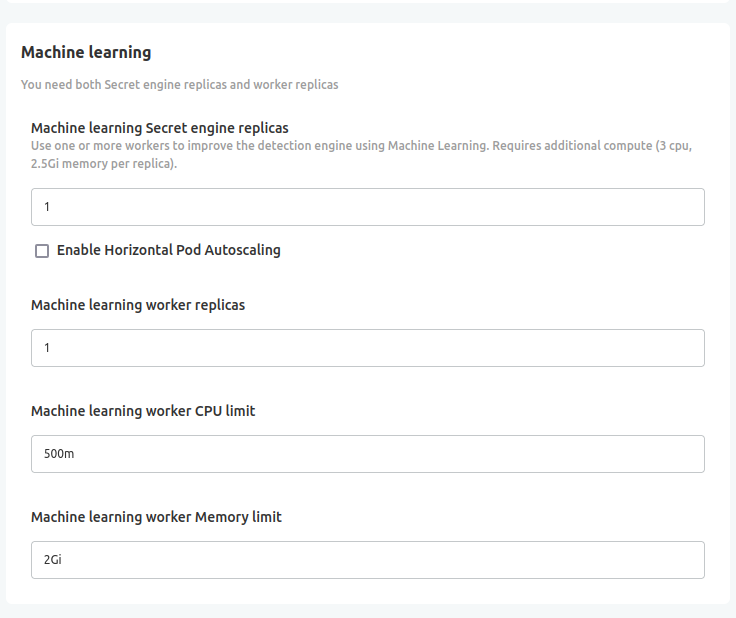
Pour activer cette fonctionnalité, définissez un nombre positif de réplicas pour le moteur ML et les workers dans votre configuration :
Installation via Helm
Pour ceux qui utilisent GitGuardian dans un environnement airgap, les noms des images requises pour le machine learning se trouvent ici.
Pour les installations Helm, consultez la documentation des values Helm pour des options de configuration détaillées. Assurez-vous de configurer un nombre positif de réplicas pour le moteur ML et les workers (la valeur par défaut est 1, donc l'absence de surcharge de cette valeur ne vous donnera pas les bonnes ressources). Configuration minimale exemple :
secretEngine:
replicas: 1
celeryWorkers:
ml-api-priority:
replicas: 1
Nous recommandons fortement d'utiliser le Horizontal Pod Autoscaling (HPA) pour le worker ml-api-priority, en particulier lors d'un backfill sur tous vos incidents. Pour plus d'informations, consultez notre guide Autoscaling.
Réduire la priorité du ML
Comme le Secret ML Engine a des exigences matérielles élevées, vous pouvez vouloir réduire sa priorité pour garantir que tous les autres pods soient ordonnancés avant. Cela peut être fait avec une ressource cluster-wide appelée PriorityClass.
Déclarez une PriorityClass dans votre cluster :
---
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: ml-priority
labels:
{{- include "gim.labels" $ | nindent 4 }}
value: -10 # see how to set this value with your cluster administrator
globalDefault: false
description: "Lower priority class for ML secretEngine pods that can be preempted."
Puis, utilisez simplement cette priorityClass dans les values GitGuardian :
secretEngine:
priorityClassName: ml-priority
Enrichir les incidents passés
Ce processus de backfill applique deux fonctionnalités basées sur le ML à vos incidents passés :
- False Positive Remover - détecte automatiquement et tague les incidents susceptibles d'être de faux positifs
- Secret Enricher - enrichit les incidents génériques avec des types de secrets précis (par ex. « Redis Credentials » au lieu de « Generic Database Assignment »)
Lorsque vous activez le Machine Learning sur votre instance GitGuardian pour la première fois, tous les incidents en temps réel seront automatiquement analysés par le moteur ML, et le playbook Auto-ignore false positive sera activé par défaut.
Voici les étapes pour enrichir les incidents passés :
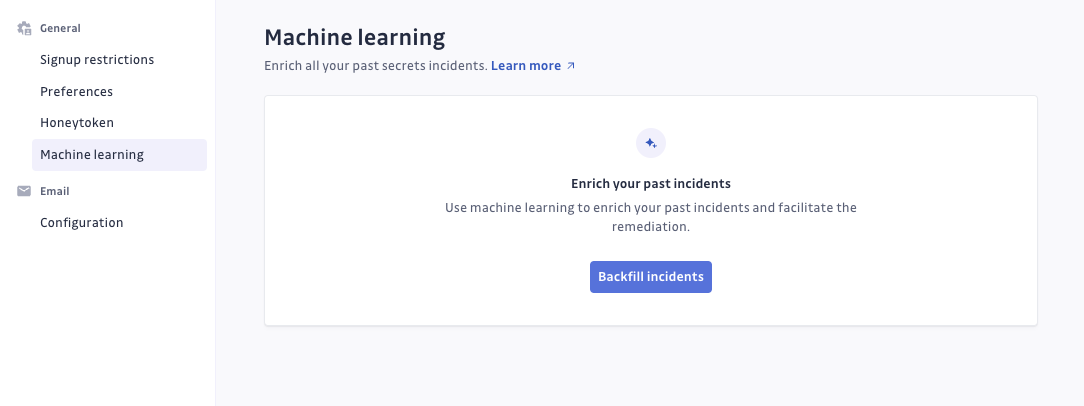
- Naviguez jusqu'à l'Admin area de votre instance GitGuardian. Vous devez avoir les privilèges admin pour continuer.
- Dans l'Admin area, naviguez jusqu'à Settings > Machine Learning.
- Cliquez sur Backfill Incidents pour appliquer le modèle ML aux incidents passés.
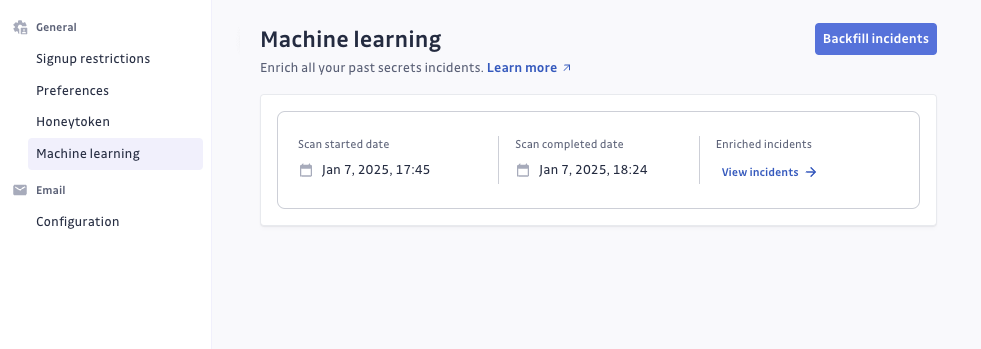
Une fois le processus de backfill terminé, un message de confirmation apparaîtra, accompagné d'un lien qui vous redirigera vers votre page d'incidents, filtrée par le tag « false positives ».
- Le processus de backfill ne peut pas être annulé une fois démarré.
- La durée de ce processus dépend du nombre d'incidents analysés, allant de quelques minutes à plusieurs jours.
- Pendant le processus de backfill, le traitement des incidents en temps réel sera retardé. Il est donc recommandé de planifier cette tâche en dehors des heures de bureau pour minimiser les perturbations.

