Autoscaling
Prérequis pour l'autoscaling
Vous pouvez utiliser soit Kubernetes HPA (Horizontal Pod Autoscaler) soit KEDA (Kubernetes Event-Driven Autoscaler) pour l'autoscaling. Les deux s'appuient sur les mêmes métriques mais ont des exigences différentes.
- HPA : intégré à Kubernetes, lit les métriques depuis Metrics Server ou depuis les métriques externes envoyées par Prometheus Adapter. Un peu moins réactif que KEDA. Ne peut pas descendre à zéro replica.
- KEDA : lit les événements depuis diverses sources (ici Prometheus). Scaling plus rapide. Peut descendre à zéro replica. Non disponible sur les installations basées sur KOTS.
Composants requis
Selon la méthode d'autoscaling choisie, vous aurez besoin de différents composants installés dans votre cluster :
| Composant | HPA | KEDA |
|---|---|---|
| Serveur Prometheus | Requis | Requis |
| Prometheus adapter | Requis | Non requis |
| Contrôleur KEDA | Non requis | Requis |
HPA nécessite Prometheus adapter pour exposer ces métriques à l'API metrics de Kubernetes, tandis que KEDA peut interroger Prometheus directement.
Installation du serveur Prometheus
Les deux méthodes d'autoscaling nécessitent un Prometheus qui collecte les métriques de l'application GitGuardian. Deux configurations sont supportées, selon que vous exécutez ou non le Prometheus Operator dans votre cluster.
Quelle que soit l'option choisie, l'application GitGuardian doit d'abord être configurée pour exposer ses métriques, sinon Prometheus collecte des endpoints vides. Voir Autoriser la collecte des métriques pour activer l'export de l'application.
Un serveur Prometheus standalone ne lit pas les ressources ServiceMonitor — il ne collecte que ce que son propre fichier de configuration liste. Ainsi, les objets ServiceMonitor intégrés au chart GitGuardian n'ont aucun effet sur un serveur standalone, et vous devez ajouter une configuration de scrape manuelle à la place.
- Option A (recommandée) — si vous exécutez déjà, ou êtes prêt à installer,
kube-prometheus-stack(inclut l'opérateur + un Prometheus managé). Le chart GitGuardian fournit les objetsServiceMonitor, donc la collecte se limite à les activer. - Option B — si vous voulez un Prometheus autonome unique sans opérateur. Vous écrivez la configuration de scrape à la main.
Ajoutez le dépôt Helm de la communauté Prometheus (utilisé par les deux options) :
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
Option A (recommandée) : kube-prometheus-stack avec ServiceMonitors
Pour l'autoscaling, vous n'avez besoin que de l'opérateur (pour traiter les objets ServiceMonitor) et de l'instance Prometheus elle-même. Désactivez tous les autres composants pour garder l'installation légère. Créez un kube-prometheus-stack-values.yaml :
# L'opérateur (prometheusOperator) et Prometheus restent activés par défaut —
# tout ce qui suit est de la surveillance à l'échelle du cluster dont l'autoscaling n'a pas besoin.
alertmanager:
enabled: false
grafana:
enabled: false
nodeExporter:
enabled: false # désactive le sous-chart prometheus-node-exporter
kubeStateMetrics:
enabled: false # désactive le sous-chart kube-state-metrics
defaultRules:
create: false # ignore les règles d'alerte/enregistrement Kubernetes intégrées
# Ignore le scraping du control-plane Kubernetes et des composants nodes
kubeApiServer:
enabled: false
kubelet:
enabled: false
kubeControllerManager:
enabled: false
coreDns:
enabled: false
kubeDns:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
kubeProxy:
enabled: false
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--create-namespace \
-f kube-prometheus-stack-values.yaml
Le Prometheus managé est ensuite accessible dans le cluster à l'adresse http://kube-prometheus-stack-prometheus.monitoring.svc.cluster.local:9090.
Activez les objets ServiceMonitor GitGuardian dans votre local-values.yaml :
observability:
exporters:
statefulAppExporter:
enabled: true
serviceMonitors:
enabled: true
labels:
# Doit correspondre au nom de la release Helm de votre installation kube-prometheus-stack.
# Le Prometheus du stack ne sélectionne que les ServiceMonitors portant ce label.
release: kube-prometheus-stack
release est obligatoirePar défaut, le Prometheus du stack a serviceMonitorSelector: {matchLabels: {release: <stack-release-name>}}. Un ServiceMonitor sans ce label exact est ignoré silencieusement — pas de cibles, pas de métriques, et le Prometheus Adapter finit par n'exposer aucune donnée. Soit vous définissez le label comme montré ci-dessus, soit vous positionnez prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false sur le stack pour qu'il sélectionne tous les ServiceMonitor.
Après le helm upgrade du chart GitGuardian, confirmez que les cibles sont bien prises en compte (état UP) dans l'interface Prometheus sous Status > Targets, ou :
kubectl -n monitoring port-forward svc/kube-prometheus-stack-prometheus 9090
# puis naviguez sur http://localhost:9090/targets et cherchez serviceMonitor/<gim-namespace>/...
Option B : Prometheus standalone avec configuration de scrape manuelle
Installez le serveur standalone :
helm install prometheus prometheus-community/prometheus \
--namespace monitoring \
--create-namespace \
--set alertmanager.enabled=false \
--set prometheus-pushgateway.enabled=false
Le serveur est ensuite accessible dans le cluster à l'adresse http://prometheus-server.monitoring.svc.cluster.local:80.
Comme le serveur standalone ignore les objets ServiceMonitor, ajoutez un job de scrape pointant vers les endpoints de métriques GitGuardian. La métrique de longueur de queue Celery (gim_celery_queue_length) est publiée par l'app exporter, un endpoint d'agrégation unique — une cible statique suffit donc. Définissez ceci dans les values du chart Helm de Prometheus standalone :
extraScrapeConfigs: |
- job_name: "gim"
static_configs:
# Remplacez <gim-namespace> par le namespace dans lequel votre release GitGuardian est installée
- targets: ["app-exporter.<gim-namespace>.svc.cluster.local:9808"]
metric_relabel_configs:
# La règle de l'adapter mappe les métriques à un namespace (overrides.namespace), donc la
# série doit porter un label `namespace`. Une cible statique n'en a pas, donc on le dérive
# depuis le hostname de l'instance : app-exporter.<namespace>.svc... -> <namespace>
- source_labels: [instance]
regex: '.*\.([^.]+)\.svc.*'
target_label: namespace
action: replace
replacement: '$1'
<gim-namespace> dans app-exporter.<gim-namespace>.svc.cluster.local est le namespace de votre release GitGuardian — remplacez-le par le namespace dans lequel vous avez effectué l'installation. Le bloc metric_relabel_configs dérive ensuite le label namespace à partir de ce que vous avez défini, donc gardez les deux cohérents.
Le service app-exporter n'existe que lorsque l'exporter d'agrégation est activé — définissez observability.exporters.statefulAppExporter.enabled: true dans vos values GitGuardian.
Pour l'autoscaling du Machine Learning Secret Engine, vous avez également besoin de bentoml_service_request_in_progress, qui est servi par le secret engine lui-même plutôt que par l'app exporter. Ajoutez une seconde cible statique pour lui (le port 3000 est la valeur par défaut de secretEngine.port — ne le modifiez que si vous avez surchargé cette valeur) :
- job_name: "gim-ml-secret-engine"
metrics_path: /metrics
static_configs:
# Remplacez <gim-namespace> par votre namespace, et 3000 si vous avez changé secretEngine.port
- targets: ["ml-secret-engine.<gim-namespace>.svc.cluster.local:3000"]
metric_relabel_configs:
- source_labels: [instance]
regex: '.*\.([^.]+)\.svc.*'
target_label: namespace
action: replace
replacement: '$1'
observability.serviceMonitorsConservez observability.serviceMonitors.enabled: false (valeur par défaut) pour cette option. Une installation Prometheus standalone n'enregistre pas les CRDs monitoring.coreos.com (ceux-ci arrivent avec le Prometheus Operator). Si vous l'activez, le chart GitGuardian essaie de créer des objets ServiceMonitor dont la CRD est absente et le helm install/helm upgrade échoue avec une erreur no matches for kind "ServiceMonitor". Le serveur standalone ignorerait de toute façon ces objets — la collecte ici provient uniquement de la configuration de scrape ci-dessus.
Installation de Prometheus adapter
Si vous choisissez HPA pour l'autoscaling, installez Prometheus Adapter pour exposer les métriques Prometheus à l'API metrics de Kubernetes. Faites pointer prometheus.url/prometheus.port vers le Prometheus que vous avez installé ci-dessus — c'est la mauvaise configuration la plus courante.
Pour l'Option A (kube-prometheus-stack) :
helm install prometheus-adapter prometheus-community/prometheus-adapter \
--namespace monitoring \
--set prometheus.url=http://kube-prometheus-stack-prometheus.monitoring.svc.cluster.local \
--set prometheus.port=9090
Pour l'Option B (serveur standalone) :
helm install prometheus-adapter prometheus-community/prometheus-adapter \
--namespace monitoring \
--set prometheus.url=http://prometheus-server.monitoring.svc.cluster.local \
--set prometheus.port=80
Si prometheus.url pointe vers un service qui n'existe pas (par exemple, vous avez migré du serveur standalone vers le stack mais laissé l'adapter sur l'ancienne URL), l'adapter reste AVAILABLE=True mais expose zéro métrique. Vérifiez avec :
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq '.resources[].name'
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1" | jq '.resources[].name'
Une liste resources vide signifie que l'adapter n'atteint aucune série correspondante — vérifiez d'abord l'URL, puis les règles.
Voir la section Configuration de Prometheus Adapter ci-dessous pour les règles à ajouter.
Installation du contrôleur KEDA
Installez le contrôleur KEDA pour activer l'autoscaling. Vous pouvez l'installer à l'aide du chart Helm KEDA avec les commandes suivantes :
helm repo add kedacore https://kedacore.github.io/charts
helm install keda kedacore/keda \
--namespace keda \
--create-namespace
Vous devez configurer les values Helm de votre chart GitGuardian pour permettre à KEDA de se connecter à votre serveur Prometheus :
autoscaling:
keda:
prometheus:
metadata:
# Utilisez l'adresse du serveur Prometheus de votre installation :
# Option A (kube-prometheus-stack) : http://kube-prometheus-stack-prometheus.monitoring.svc.cluster.local:9090
# Option B (serveur standalone) : http://prometheus-server.monitoring.svc.cluster.local:80
serverAddress: http://prometheus-server.monitoring.svc.cluster.local:80
# Facultatif. En-têtes personnalisés à inclure dans la requête
customHeaders: X-Client-Id=cid,X-Tenant-Id=tid,X-Organization-Id=oid
# Facultatif. Spécifie le mode d'authentification (basic, bearer, tls)
authModes: bearer
# Facultatif. Spécifie la ressource TriggerAuthentication à utiliser lorsque authModes est spécifié.
authenticationRef:
name: keda-prom-creds
Un ScaledObject et un hpa seront créés dans le namespace GitGuardian.
Autoscaling des workers
L'autoscaling permet le scaling dynamique des pods worker en fonction de la longueur de la queue de tâches Celery utilisée comme métrique externe pour les décisions de scaling, améliorant l'efficacité et les performances tout en optimisant les coûts en ressources.
Pour activer l'autoscaling basé sur les longueurs de queue Celery, vous devez d'abord autoriser la collecte des métriques afin que l'application expose ses métriques.
Si vous utilisez KEDA, la configuration de Prometheus adapter n'est pas nécessaire.
Configuration de Prometheus adapter
Configurez Prometheus adapter pour exposer les longueurs de queue Celery en tant que métriques externes. Cela se fait en configurant une règle personnalisée dans la configuration de Prometheus Adapter.
La règle suivante doit être ajoutée aux values Helm de votre Prometheus Adapter pour exposer les longueurs de queue Celery :
rules:
external:
- seriesQuery: '{__name__="gim_celery_queue_length",queue_name!=""}'
metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>}) by (queue_name)
resources:
namespaced: true
overrides:
namespace:
resource: namespace
Si vous utilisez Machine Learning, vous aurez également besoin de cette règle :
rules:
external:
- seriesQuery: '{__name__="bentoml_service_request_in_progress",exported_endpoint!=""}'
resources:
namespaced: false
metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)
Comportement de l'autoscaling
Le comportement suivant sera appliqué :
- Scaling Up : si la longueur d'une queue Celery dépasse 10 tâches par replica de worker actuel, le nombre de replicas sera augmenté, à condition que le nombre actuel de replicas soit inférieur à la limite maximum spécifiée.
- Scaling Down : si le nombre de tâches par replica de worker actuel reste inférieur à 10 pendant une période continue de 5 minutes, le nombre de replicas sera diminué, à condition que le nombre actuel de replicas soit supérieur à la limite minimum spécifiée.
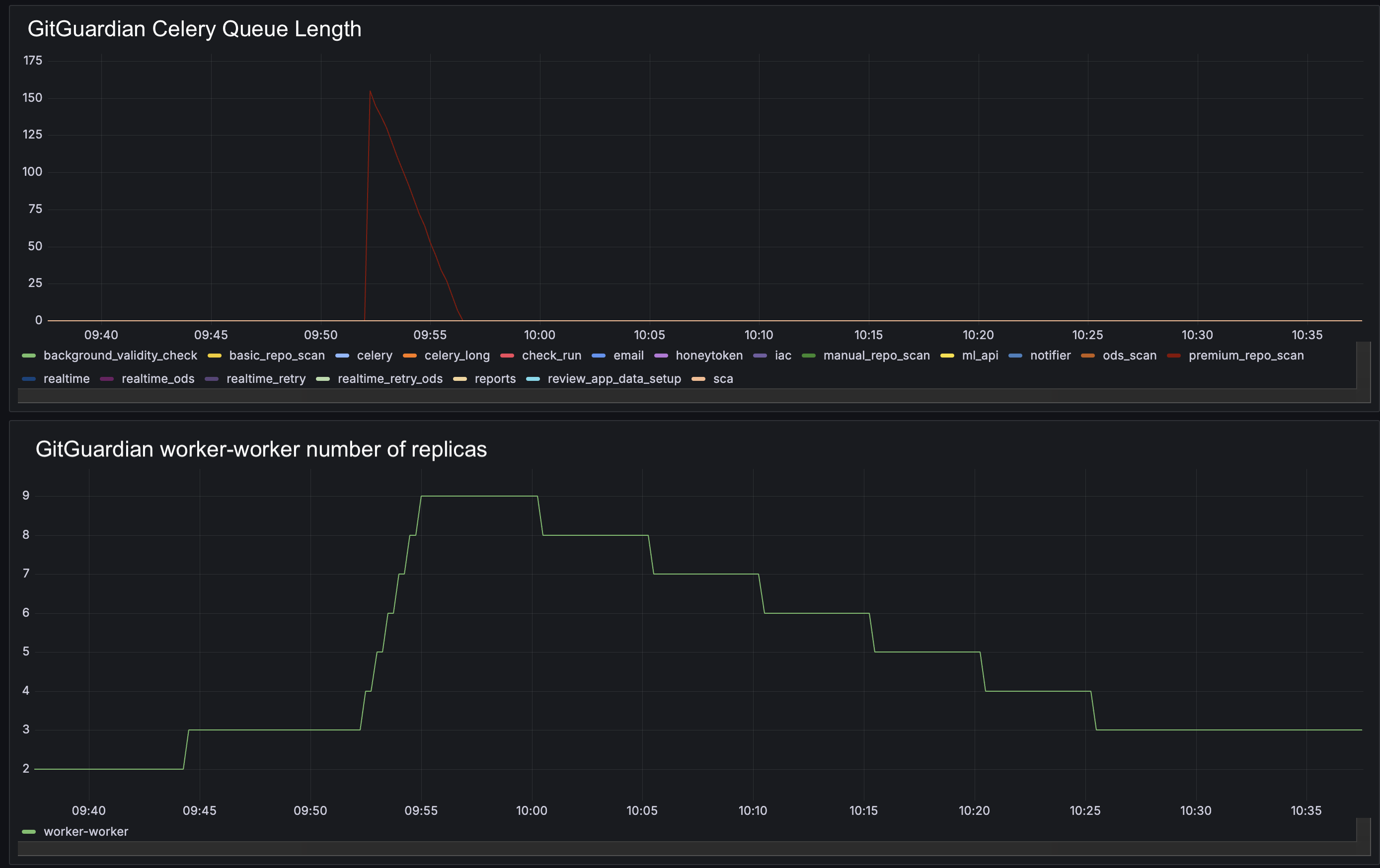
En utilisant KEDA, lorsque la queue Celery est vide, le worker passera à un état inactif, ce qui entraînera la mise à l'échelle du nombre de replicas jusqu'à zéro.
Installation basée sur KOTS
L'installation basée sur KOTS ne permet que l'autoscaling HPA.
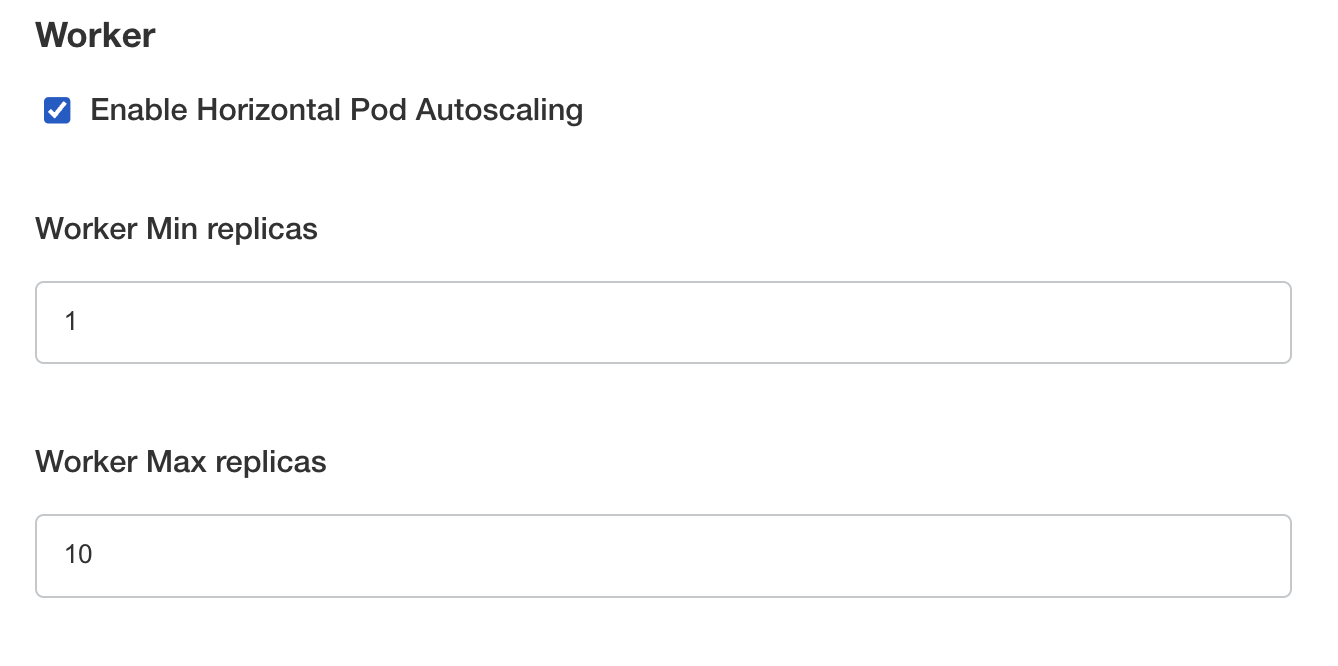
Naviguez sous Config > Scaling dans la KOTS Admin Console, vous aurez accès aux options de scaling des workers.
Pour chaque worker, vous pouvez activer l'autoscaling en cochant l'option Enable Horizontal Pod Autoscaling, puis vous pourrez spécifier le minimum et le maximum de replicas.
Installation basée sur Helm
Personnalisez les applications Helm en utilisant votre fichier local-values.yaml, soumis avec la commande helm.
Autoscaling des workers
Vous pouvez activer l'autoscaling des workers en définissant les values Helm suivantes (ici, nous activons HPA pour le worker "worker") :
celeryWorkers:
worker:
autoscaling:
hpa:
enabled: true
keda:
enabled: false
minReplicas: 1
maxReplicas: 10
Autoscaling du Machine Learning Secret Engine
Pour un autoscaling efficace du Machine Learning Secret Engine, vous devez activer l'autoscaling pour les deux :
-
Le ML Worker traitant la queue Celery (
ml-api-priority) : ce worker est responsable de la mise en file d'attente et de la répartition des tâches liées au ML. Sans autoscaling, il pourrait devenir un goulot d'étranglement, entraînant des retards dans le traitement des requêtes. -
Le Secret Engine gérant le calcul (
secretEngine) : activer l'autoscaling pour le Secret Engine garantit qu'il peut évoluer en réponse à la demande de calculs ML.
Pour activer l'autoscaling, configurez les values Helm suivantes :
# ML Secret Engine
secretEngine:
autoscaling:
hpa:
enabled: true
keda:
enabled: false
minReplicas: 1
maxReplicas: 2
celeryWorkers:
# ML Worker
ml-api-priority:
autoscaling:
hpa:
enabled: true
keda:
enabled: false
minReplicas: 1
maxReplicas: 2
Consultez la documentation de référence des values pour plus de détails.
Les paramètres Helm autoscaling.hpa.enabled et autoscaling.keda.enabled sont mutuellement exclusifs, vous devez choisir entre hpa (utilisant Prometheus adapter) et le contrôleur KEDA.

