Machine Learning
This section outlines the machine learning features implemented in GitGuardian, detailing how they work and how to activate them for Self-Hosted. Once activated, you can enrich past incidents with machine learning analysis.
For more details about the machine learning capabilities, see the Machine Learning Secret Detection documentation.
System Requirements
The ML Secret Engine requires 3 vCPU and 2.5 GiB RAM per replica. For detailed scaling guidelines, performance metrics, and infrastructure recommendations, see the Scaling documentation.
From 2025.7.0 version, Machine Learning is activated by default.
KOTS-Based Installation
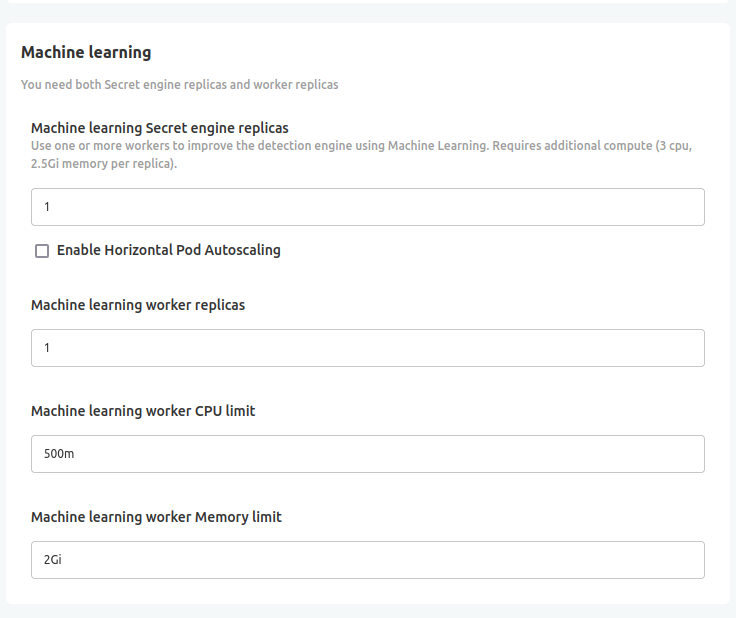
To enable this feature, set a positive number of replicas for both the ML engine and workers in your configuration:
Helm-Based Installation
For those using GitGuardian in an air-gapped environment, the names of the images required for machine learning can be found here.
For Helm-based installations, consult the Helm Values Documentation for detailed configuration options. Ensure you configure a positive number of replicas for the ML engine and workers (the default value is 1, so no override of this value will get you the correct resources). Example minimal configuration:
secretEngine:
replicas: 1
celeryWorkers:
ml-api-priority:
replicas: 1
We strongly recommend using Horizontal Pod Autoscaling (HPA) for the ml-api-priority worker, especially when performing a backfill on all your incidents. For more information, refer to our Autoscaling Guide.
Lower the priority of ML
As Secret ML Engine has high hardware requirements, you may want to lower its priority to ensure all other pods are scheduled before. This can be done with a cluster-wide Resource called PriorityClass.
Declare a PriorityClass in your cluster:
---
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: ml-priority
labels:
{{- include "gim.labels" $ | nindent 4 }}
value: -10 # see how to set this value with your cluster administrator
globalDefault: false
description: "Lower priority class for ML secretEngine pods that can be preempted."
Then, simply use that priorityClass in GitGuardian values:
secretEngine:
priorityClassName: ml-priority
Enrich Past Incidents
This backfill process applies two ML-powered features to your past incidents:
- False Positive Remover - automatically detects and tags incidents likely to be false positives
- Secret Enricher - enriches generic incidents with precise secret types (e.g., "Redis Credentials" instead of "Generic Database Assignment")
When you activate Machine Learning on your GitGuardian instance for the first time, all real-time incidents will be automatically analyzed by the ML engine, and the Auto-ignore false positive playbook will be enabled by default.
Here are the steps to enrich past incidents:
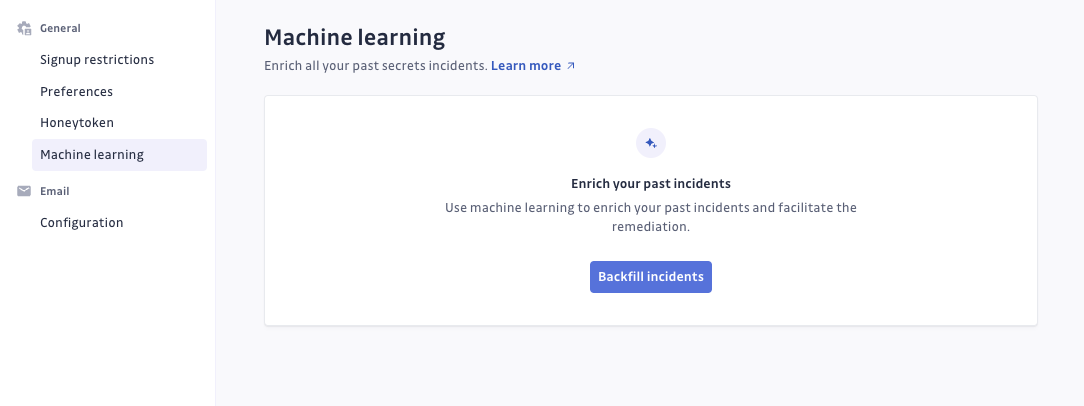
- Navigate to the Admin area of your GitGuardian instance. You must have admin privileges to proceed.
- In the Admin area, navigate to Settings > Machine Learning.
- Click on Backfill Incidents to apply the ML model to past incidents.
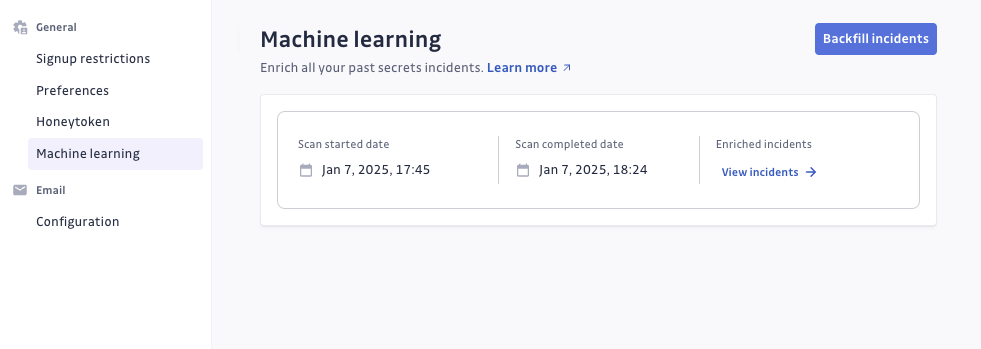
After the backfill process is completed, a confirmation message will appear, along with a link that redirects you to your incident page, filtered by the 'false positives' tag.
- The backfill process cannot be canceled once started.
- The duration of this process depends on the number of incidents being analyzed, ranging from a few minutes to several days.
- During the backfill process, real-time incidents processing will be delayed. Therefore, it is recommended to schedule this task outside of business hours to minimize disruptions.

