Non-VCS Sources
This section outlines how to activate and configure workers for non-VCS (Version Control System) integrations in Self-Hosted GitGuardian. These integrations allow you to scan messaging platforms, documentation tools, ticketing systems, and container registries for secrets.
By default, all workers for these integrations are deactivated (number of replicas set to 0).
Worker Compatibility:
- Can use default VCS workers (but dedicated workers recommended): Slack, Microsoft Teams, Confluence, Jira, and ServiceNow can optionally use the same workers as VCS sources (
worker-scanners,worker-worker,worker-long). - Require dedicated workers: All other integrations (OneDrive, SharePoint, Container Registries, Package Registries) must use their own specialized workers and cannot share VCS workers
We recommend using dedicated workers for all integrations to avoid queue congestion and ensure optimal performance.
Available Integrations
Messaging Integrations
Monitor messaging platforms for secrets in conversations and shared content.
Available sources:
Required workers:
worker-realtime-ods- Processes real-time scans and eventsworker-scanners-ods- Handles historical scans for messaging platformsworker-scanners-slack- Dedicated worker for Slack historical scans onlyworker-long-ods- Processes long-running tasks for messaging platformsworker-long-ods-io- Handles IO-intensive long-running tasks
Documentation Integrations
Scan documentation platforms and file storage services for leaked secrets.
Available sources:
Required workers:
worker-realtime-ods- Processes real-time scans and eventsworker-scanners-ods- Handles historical scans for documentation platformsworker-scanners-ods-highdisk- Required for high storage tasks (Microsoft OneDrive and SharePoint scanning)worker-long-ods- Processes long-running tasks for documentation platformsworker-long-ods-io- Handles IO-intensive long-running tasksapache-tika- Required when scanning Microsoft OneDrive and SharePoint for office document formats
Ticketing Integrations
Monitor ticketing systems for secrets in issues, comments, and attachments.
Available sources:
Required workers:
worker-realtime-ods- Processes real-time scans and eventsworker-scanners-ods- Handles historical scans for ticketing platformsworker-long-ods- Processes long-running tasks for ticketing platformsworker-long-ods-io- Handles IO-intensive long-running tasks
Container Registry Integrations
Scan container images and registries for embedded secrets.
Available sources:
Required workers:
worker-container-registries- Dedicated worker for container registry scanning tasks
Package Registry Integrations
Scan package registry artifacts for secrets across multiple package ecosystems.
Available sources:
Required workers:
worker-scanners-db-less- Dedicated worker for package registry scanning tasks
The commit-cache Redis instance is used for JFrog Package Registries scanning. If the commit-cache Redis instance is not configured, the main Redis instance will be used instead.
System Requirements
Standard Workers
Each standard worker type requires: 0.5 vCPU and 2 GiB RAM per replica
File scanner pod
For binary and file scanning (OneDrive/SharePoint): 0.5 vCPU and 500 MiB RAM per replica
High Disk Workers
For high storage requirements (OneDrive/SharePoint): Additional disk space and I/O capacity
Configuration
KOTS-Based Installation
To enable non-VCS source integrations in KOTS:
-
Access the KOTS Admin Console
-
Navigate to the Config section
-
Locate the worker configuration sections under Scaling:
- Container registries Worker
- Non-VCS Sources Workers
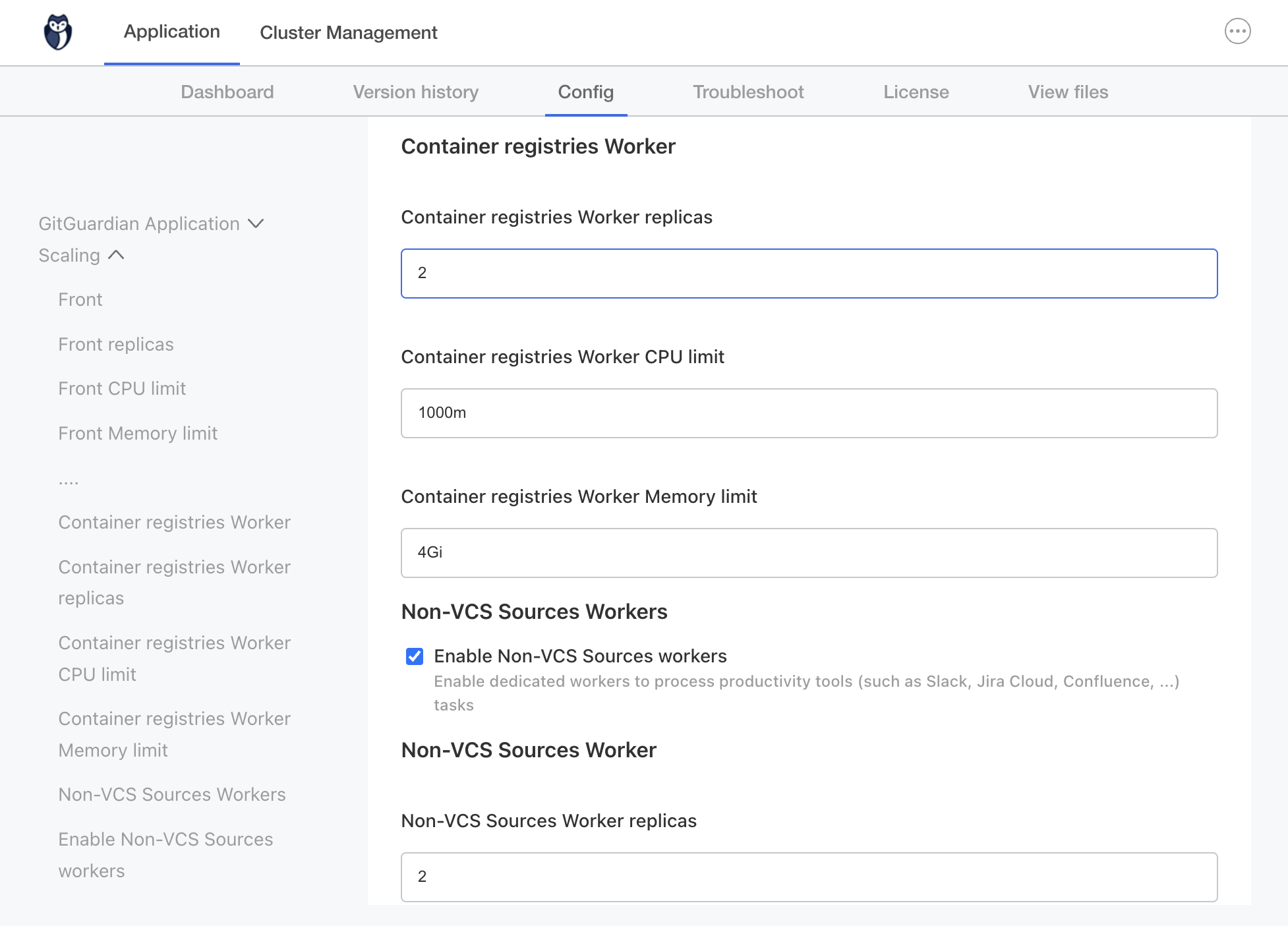
-
Set a positive number of replicas for the required workers (change from 0 to 1 or higher)
-
If using OneDrive/SharePoint, enable and set replicas in the File Scanner section
-
Save the configuration
Helm-Based Installation
For air-gapped environments, the names of the images required for file scanner can be found in the Air-gap Installation documentation.
For Helm-based installations, consult the Helm Values Documentation for detailed configuration options. Configure worker replicas in your values.yaml file.
Example minimal configuration for messaging integration:
# File scanner (for OneDrive/SharePoint)
apacheTika:
replicas: 1 # Set to 0 if not using OneDrive/SharePoint
# Celery Workers
celeryWorkers:
# Messaging, Documentation, and Ticketing workers
scanners-ods:
replicas: 1
scanners-slack:
replicas: 1 # Only needed for Slack
long-ods:
replicas: 1
long-ods-io:
replicas: 1
realtime-ods:
replicas: 1
# Container registry workers
container-registries:
replicas: 1
# High disk workers (for OneDrive/SharePoint)
scanners-ods-highdisk:
replicas: 1 # Set to 0 if not using OneDrive/SharePoint
Example configuration for documentation integration with OneDrive/SharePoint:
apacheTika:
replicas: 1
celeryWorkers:
scanners-ods:
replicas: 1
scanners-ods-highdisk:
replicas: 1 # Required for OneDrive/SharePoint
long-ods:
replicas: 1
long-ods-io:
replicas: 1
realtime-ods:
replicas: 1
Example configuration for ticketing integration:
celeryWorkers:
scanners-ods:
replicas: 1
long-ods:
replicas: 1
long-ods-io:
replicas: 1
realtime-ods:
replicas: 1
Example configuration for container registries:
celeryWorkers:
container-registries:
replicas: 1
Example configuration for package registries:
celeryWorkers:
scanners-db-less:
replicas: 1
Scaling
After enabling the basic integrations, refer to the Scaling documentation for detailed information on:
- Configuring scaling settings based on your workload
- Monitoring worker performance
- Optimizing resource allocation
- Handling increased throughput
This page focuses on initial activation - the scaling documentation covers performance optimization and capacity planning.
Notes
- Queue Isolation: Using dedicated workers prevents non-VCS sources from interfering with VCS scanning performance
- File scanner: Only required when scanning Microsoft OneDrive and SharePoint for file scanning (Office documents, PDFs, etc.)
- High Disk Workers: The
worker-scanners-ods-highdiskis specifically designed for tasks requiring significant storage, primarily Microsoft OneDrive and SharePoint scanning - Slack Special Case: Slack has its own dedicated historical scan worker (
worker-scanners-slack) in addition to the standard ODS workers - Container Isolation: Container registry scanning uses completely separate workers (
worker-container-registries) from other non-VCS sources - Package Registry Isolation: Package registry scanning requires dedicated
worker-scanners-db-lessworkers and uses thecommit-cacheRedis instance

