Secrets Detection Engine
Philosophy
Secrets detection is probabilistic: some secrets are easier to find than others. There is a trade-off between low number of false alerts and low number of missed credentials (precision/recall trade-off)
Our secrets detection engine has been running in production since 2017, analyzing billions of commits coming from GitHub. Since day one we began to train and benchmark our algorithms against the open source code. It allowed GitGuardian to build a language agnostic secrets detection engine, integrating new secrets or new way of declaring secrets really fast while keeping a really low number of false positives. We are also collecting feedbacks from the alerts we are sending including the pro bono alerts:
- Explicit feedback when a developer or security team marks an alert as a false alert.
- Implicit feedback when a developer takes down a public repository or deletes a public commit a few minutes after we sent an alert.
We are currently implementing two types of detectors:
-
Specific detectors: we implement an algorithm dedicated to looking for one specific type of secret like AWS keys, Postgres URI or SMTP credentials. This type of detector aims at having high recall and precision for the targeted type of secret. The downside of this approach is that we have to implement a lot of specific detectors to have a good coverage of all existing secrets.
-
Generic detectors: The purpose of these detectors is to catch what our specific detectors are missing with a generic approach. We will implement generic detectors capturing patterns such as
secret=\{high_entropy_string\}orpassword=xxx, email=yyy@corp.com. We can thereby achieve a low number of secrets missed even if the precision of these detectors is slightly lower than the specific ones.
You can of course choose what detectors you want to allow or deny in our different web applications.
How it works
Our secrets detection engine takes as input a Document having as parameter a string (a Git Patch, a GitHub gist, a Slack message) and an optional parameter which is the filename (secrets.py, index.html, ...)
Note that this detection engine can use the filename when available in a pre-validation step: for example we won't scan an image or a video file since nobody puts secrets in it.
We currently have the following ban-lists in place:
- We do not scan binary files such as
jpg,tar.*, ... - We exclude some filepaths using the following regexes:
node_modules(/|\\)
vendors?(/|\\)
top-1000\.txt$
\.sops$
\.sops\.yaml$
- In most cases, we do not scan documents with the following extensions because they bring a lot of false positives and almost no real secrets:
["html", "css", "md", "lock", "storyboard", "xib"]
Tao of our secrets detection engine
- 🎯 High precision: We want to keep a low number of false positives to avoid alert fatigue.
- 🔐 High recall: We want to keep a low number of missed secrets to keep our customers safe.
- ⚡ Speed: While speed is less important than recall and precision our secrets detection engine is designed to be fast and scan a common Git repository history in less than a minute.
- 👥 Community and customer driven: Our engine is constantly trained and improved by feedbacks from hundreds of thousands developers using our applications and by feedbacks of our customers.
Main features
Broad coverage with 450+ specific detectors
We have developed the vastest library of specific detectors being able to detect more than 450 different types of secrets (10 times more than the current competition). You can find the exhaustive list here.
Detecting secrets with multiples matches and multi-line secrets
GitGuardian supports the detection of multi-matches secrets such as oauth client_id and client_secret, database credentials, SMTP credentials...
GitGuardian supports the detection of multi-line secrets such as private keys.
For example we are able to detect AWS keys from the following snippet and the output will be two matches: one for the client id and one for the client secret.
input: 'id=AKIAFJKR45SAWSZ5XDF3, client_secret: hjshnk5ex5u34565d4654HJKGjhz545d89sjkjka'
output:
client_id: AKIAFJKR45SAWSZ5XDF3
client_secret: hjshnk5ex5u34565d4654HJKGjhz545d89sjkjka
Example for database credentials:
input: |
dbusername = admin
dbpassword = 8095uohoiw4ur90
dbhost = db-postgres-nyc1-1111-do-user-111111-0.db.ondigitalocean.com
dbport = 25060
dbdatabase = defaultdb
dbsslmode = require
output:
username: admin
password: 8095uohoiw4ur90
host: db-postgres-nyc1-1111-do-user-111111-0.db.ondigitalocean.com
port: 25060
Automatic de-duplication
- If two detectors match the same characters and have the same matches we drop the output of the detectors bringing less information.
For example the following content slack_token="xoxp-198947049743-7861195093-830655328819-9d40a979cac97bccf1190afb660b37e1" triggers two detectors:
our slack_user_token detector and our detector catching generic secrets (token={high_entropy_string}). We only keep the results of the slack_user_token
detector in order to reduce alert fatigue and attach the maximum information to help with the remediation process.
Detecting prefixed Base64 encoded secrets
Recent frameworks like Kubernetes use Base64-encoded secrets and it is becoming pretty common to see Base64-encoded secrets. We are able to detect prefixed secrets encoded in Base64 like private keys.
Add insights to secrets to ease the work of security engineers and analysts
We attach insights to secrets so the application security analysts can have more context information for the remediation. Currently we support the following insights:
test_file: We found the secret in a test context (test folder, test filename).sensitive_file: We found the secret in a document with a filename considered as sensitive (.env,credentials.json, ...).whitelisted: The secret has been white-listed by the developer that wrote the code.decoded value for encoded secret: We can attach the decoded secret value to encoded secret.
Limitations
- We are not able to scan binary files (for now). Some binary filenames can contain secrets, such as
.pycfiles in Python for example. - The number of secrets detected per detector and per file is limited to 8 by default. This limit is here to avoid receiving a huge volume of alerts for the same document. We always recommend to look into the document where we detected a secret, there might be other sensitive information that we didn't highlight.
Architecture
Our secret detection engine is based on the following logic:
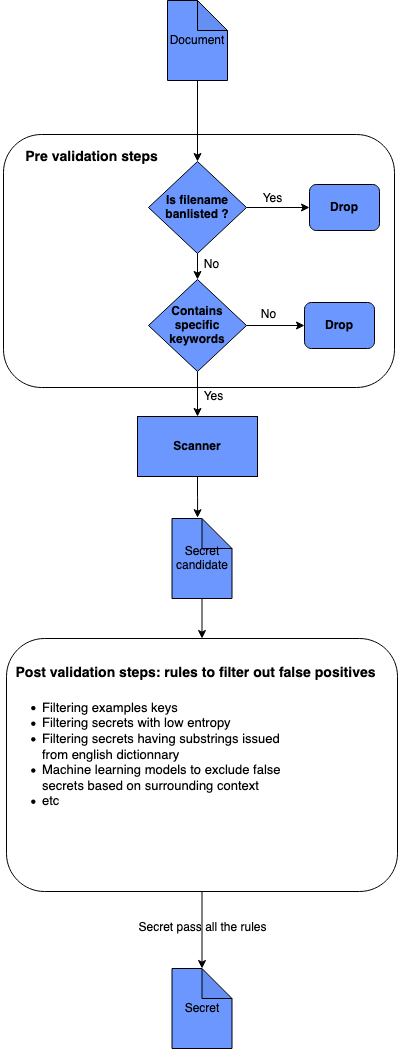
We use PreValidators to remove some filenames bringing false positives or to select a document based on the presence of a keyword. For example every SendGrid API key must start with the prefix SG., we can discard all documents that don't contain this prefix. These pre-validation steps are the first steps of our secrets detection engine. You can find more information about pre-validators here.
We then use PostValidators to validate if our secrets candidate are real secrets. We configure PostValidators for each Detector so we can achieve the best trade-off between recall and precision. You can find more information about all the PostValidators we currently use and support here.
Our Scanner is a collection of detectors that scans a Document and yield Secret objects.

